“we r hot” show dance rehearsal with commentary (hilarious sexy fun)
After her wild Ukulele post popped up on her crazy subterranean TikTok account and a couple of random posts since, today Billi Eilish posted what appears to be a impromptu reversal video with some hilarious commentary. Set to the song “Lost Cause” (very hot now).
The account which only has 14 videos since it first popped up and has 35.4 million followers (of course!) and 190.3 millions likes, and the video (below) got a whopping 3.2 million in the first hour and currently has accumulated 80 million views to date. The first full video on the account – other than the Ukulele post mentioned above. That one went live back on November 13, 2020.
It’s pretty clear from the humor, voice over and the attitude that Billie loves the vibe and spontaneity of TikTok and this video and her rogue account style fits right in!
Even at the relatively elderly summit of 19 her sultry, dark style along with top of the world presence continues to command loyalty and love for her music and style. Her recent biographical photo book was also a hit and the new songs will likely continue at the top of our summer list. The documentary is great also.
Oh, and the WORLD TOUR 2022 starts in February! Kicking off in Smoothie King Center, New Orleans, LA, however, unfortunately tickets for that show has since been SOLD OUT!
Leaked internal documents suggest Facebook – which recently renamed itself Meta – is doing far worse than it claims at minimizing COVID-19 vaccine misinformation on the Facebook social media platform.
Online misinformation about the virus and vaccines is a major concern. In one study, survey respondents who got some or all of their news from Facebook were significantly more likely to resist the COVID-19 vaccine than those who got their news from mainstream media sources.
As a researcher who studies social and civic media, I believe it’s critically important to understand how misinformation spreads online. But this is easier said than done. Simply counting instances of misinformation found on a social media platform leaves two key questions unanswered: How likely are users to encounter misinformation, and are certain users especially likely to be affected by misinformation? These questions are the denominator problem and the distribution problem.
The COVID-19 misinformation study, “Facebook’s Algorithm: a Major Threat to Public Health”, published by public interest advocacy group Avaaz in August 2020, reported that sources that frequently shared health misinformation — 82 websites and 42 Facebook pages — had an estimated total reach of 3.8 billion views in a year.
At first glance, that’s a stunningly large number. But it’s important to remember that this is the numerator. To understand what 3.8 billion views in a year means, you also have to calculate the denominator. The numerator is the part of a fraction above the line, which is divided by the part of the fraction below line, the denominator.
Getting some perspective
One possible denominator is 2.9 billion monthly active Facebook users, in which case, on average, every Facebook user has been exposed to at least one piece of information from these health misinformation sources. But these are 3.8 billion content views, not discrete users. How many pieces of information does the average Facebook user encounter in a year? Facebook does not disclose that information.
Without knowing the denominator, a numerator doesn’t tell you very much. The Conversation U.S., CC BY-ND
Market researchers estimate that Facebook users spend from 19 minutes a day to 38 minutes a day on the platform. If the 1.93 billion daily active users of Facebook see an average of 10 posts in their daily sessions – a very conservative estimate – the denominator for that 3.8 billion pieces of information per year is 7.044 trillion (1.93 billion daily users times 10 daily posts times 365 days in a year). This means roughly 0.05% of content on Facebook is posts by these suspect Facebook pages.
The 3.8 billion views figure encompasses all content published on these pages, including innocuous health content, so the proportion of Facebook posts that are health misinformation is smaller than one-twentieth of a percent.
Is it worrying that there’s enough misinformation on Facebook that everyone has likely encountered at least one instance? Or is it reassuring that 99.95% of what’s shared on Facebook is not from the sites Avaaz warns about? Neither.
Misinformation distribution
In addition to estimating a denominator, it’s also important to consider the distribution of this information. Is everyone on Facebook equally likely to encounter health misinformation? Or are people who identify as anti-vaccine or who seek out “alternative health” information more likely to encounter this type of misinformation?
Another social media study focusing on extremist content on YouTube offers a method for understanding the distribution of misinformation. Using browser data from 915 web users, an Anti-Defamation League team recruited a large, demographically diverse sample of U.S. web users and oversampled two groups: heavy users of YouTube, and individuals who showed strong negative racial or gender biases in a set of questions asked by the investigators. Oversampling is surveying a small subset of a population more than its proportion of the population to better record data about the subset.
The researchers found that 9.2% of participants viewed at least one video from an extremist channel, and 22.1% viewed at least one video from an alternative channel, during the months covered by the study. An important piece of context to note: A small group of people were responsible for most views of these videos. And more than 90% of views of extremist or “alternative” videos were by people who reported a high level of racial or gender resentment on the pre-study survey.
While roughly 1 in 10 people found extremist content on YouTube and 2 in 10 found content from right-wing provocateurs, most people who encountered such content “bounced off” it and went elsewhere. The group that found extremist content and sought more of it were people who presumably had an interest: people with strong racist and sexist attitudes.
The authors concluded that “consumption of this potentially harmful content is instead concentrated among Americans who are already high in racial resentment,” and that YouTube’s algorithms may reinforce this pattern. In other words, just knowing the fraction of users who encounter extreme content doesn’t tell you how many people are consuming it. For that, you need to know the distribution as well.
Superspreaders or whack-a-mole?
A widely publicized study from the anti-hate speech advocacy group Center for Countering Digital Hate titled Pandemic Profiteers showed that of 30 anti-vaccine Facebook groups examined, 12 anti-vaccine celebrities were responsible for 70% of the content circulated in these groups, and the three most prominent were responsible for nearly half. But again, it’s critical to ask about denominators: How many anti-vaccine groups are hosted on Facebook? And what percent of Facebook users encounter the sort of information shared in these groups?
Without information about denominators and distribution, the study reveals something interesting about these 30 anti-vaccine Facebook groups, but nothing about medical misinformation on Facebook as a whole.
These types of studies raise the question, “If researchers can find this content, why can’t the social media platforms identify it and remove it?” The Pandemic Profiteers study, which implies that Facebook could solve 70% of the medical misinformation problem by deleting only a dozen accounts, explicitly advocates for the deplatforming of these dealers of disinformation. However, I found that 10 of the 12 anti-vaccine influencers featured in the study have already been removed by Facebook.
Consider Del Bigtree, one of the three most prominent spreaders of vaccination disinformation on Facebook. The problem is not that Bigtree is recruiting new anti-vaccine followers on Facebook; it’s that Facebook users follow Bigtree on other websites and bring his content into their Facebook communities. It’s not 12 individuals and groups posting health misinformation online – it’s likely thousands of individual Facebook users sharing misinformation found elsewhere on the web, featuring these dozen people. It’s much harder to ban thousands of Facebook users than it is to ban 12 anti-vaccine celebrities.
This is why questions of denominator and distribution are critical to understanding misinformation online. Denominator and distribution allow researchers to ask how common or rare behaviors are online, and who engages in those behaviors. If millions of users are each encountering occasional bits of medical misinformation, warning labels might be an effective intervention. But if medical misinformation is consumed mostly by a smaller group that’s actively seeking out and sharing this content, those warning labels are most likely useless.
Trying to understand misinformation by counting it, without considering denominators or distribution, is what happens when good intentions collide with poor tools. No social media platform makes it possible for researchers to accurately calculate how prominent a particular piece of content is across its platform.
Facebook restricts most researchers to its Crowdtangle tool, which shares information about content engagement, but this is not the same as content views. Twitter explicitly prohibits researchers from calculating a denominator, either the number of Twitter users or the number of tweets shared in a day. YouTube makes it so difficult to find out how many videos are hosted on their service that Google routinely asks interview candidates to estimate the number of YouTube videos hosted to evaluate their quantitative skills.
As the societal impacts of social media become more prominent, pressure on the big tech platforms to release more data about their users and their content is likely to increase. If those companies respond by increasing the amount of information that researchers can access, look very closely: Will they let researchers study the denominator and the distribution of content online? And if not, are they afraid of what researchers will find?
Federal judge quashes Bezos’ lawsuit against NASA over SpaceX contract In the ongoing and ever escalating feud between worlds 1st & 2nd biggest billionaires things just got meme-ier Sad, bad loser Bezos turned to the courts when his dick-rocket compensation company was passed over for the 2.9 billion $ manned lunar lander contract that was awarded exclusively to Musk’s SpaceX.
Above: Photo Collage / Lynxotic / Tesla / Various Sources
Musk’s Twitter Feud with Bezos goes back to the early days of Blue Origin, when Musk dubbed the future penile manufacturer a “copy cat” and proceeded by lambasting his “blue balls” marketing campaign and then turning the focus to his full time career as a litigant in sour-grapes lawsuits…
The complaint was brought against NASA by Blue Origin via the government watchdog, the Government Accountability Office, claiming that the decision, which NASA said was made for reasons of budget, was “anticompetitive”.
Let that sink in, Bezos, the man behind amazon’s well known and all pervasive anticompetitive marketplace practices, which are currently under siege by the FTC and multiple governments around the globe, feels that it’s “unfair” that his “rocket-looks-like-a-xxx” manufacturing company was not picked to get a multibillion dollar contract.
“Anticompetitive” is a concept not unfamiliar to the ex-Amazon CEO
Above: Screenshot of Reuters Article
A recent Reuters Special report outlined how a treasure trove of internal documents exposed a pattern that nails just what “anticompetitive” looks like: at Amazon.
Though accusations were denied by the company, Reuters research into the voluminous documentation revealed that ” the company ran a systematic campaign of creating knockoffs and manipulating search results to boost its own product lines in India, one of the company’s largest growth markets. The employees also stoked sales of Amazon private-brand products by rigging Amazon’s search results so that the company’s products would appear, as one 2016 strategy report for India put it, “in the first 2 or three … search results” when customers were shopping…”
Boo hoo? Musk, ever the master of meme generation, celebrated the news with a meme-tweet of Sly Stallone’s Judge Dredd with the caption “You have been Judged”. What Bezos will not be participating in is The Human Landing System program, a NASA initiative to design a lunar landing system that could return humans to the moon in 2024.
Finally: the whole package – and a convenient way to prove vaccination status
Now that the iOS 15.1 update is available for the general public featuring the ability to add your proof of vaccination status to the Health app and then create a vaccination ID card in Apple Wallet, it’s time to jump right in and make it happen
Many businesses, venues, restaurants, and more are requiring proof of vaccination for entry. For example California is the first state where proof of COVID vaccination or negative test is mandatory for indoor events over 1,000 people.
The new feature in iOS 15.1 is made possible by the support Smart Health Cards which are valid for California, Louisiana, New York, Virginia, Hawaii, and some Maryland counties, as do Walmart, Sam’s Club, and CVS Health.
Above: ID in iPhone Wallet
Therefore, using this system you would be able to to look up the information in state databases, if you are in any of the states listed above, but if you were vaccinated through at Walmart or CVS it will also be feasible retrieve your data from them to add your information to the Health and Wallet.
Once you have gone to the web site for your state, for example in California it would be found at https://myvaccinerecord.cdph.ca.gov where you can type in personal information such as name and date of birth to get access to your records and status.
Though iOS 15 already had the ability to download the information to your Health app, and you could do that since the official launch of iOS 15, the last step, adding an ID to your wallet from the health app has not been possible until the new upgrade to iOS 15.1.
The record is locked to your name and can only be used by you. There will be a QR code that you will first download to your health app on the iPhone, then, once it is in the health app there will be a prompt to allow you to “add to wallet”. By clicking that link, a vaccination ID card, with the QR code will be generated and added to your wallet. See video above for more detailed, step-by-step explanation.
iOS 15.1 is available under > General > software update in your phone’s Settings app starting today.
Tap the download link on your iPhone or iPod touch.
Tap Add to Health to add the record to the Health app.
Tap Done.
Once the ID is in the health app a button / prompt appears “add to wallet”.
Digital rights advocates on Tuesday welcomed Facebook’s announcement that it plans to jettison its facial recognition system, which critics contend is dangerous and often inaccurate technology abused by governments and corporations to violate people’s privacy and other rights.
“Corporate use of face surveillance is very dangerous to people’s privacy.”
Adam Schwartz, a senior staff attorney at the Electronic Frontier Foundation (EFF) who last month called facial recognition technology “a special menace to privacy, racial justice, free expression, and information security,” commended the new Facebook policy.
“Facebook getting out of the face recognition business is a pivotal moment in the growing national discomfort with this technology,” he said. “Corporate use of face surveillance is very dangerous to people’s privacy.”
The social networking giant first introduced facial recognition software in late 2010 as a feature to help users identify and “tag” friends without the need to comb through photos. The company subsequently amassed one of the world’s largest digital photo archives, which was largely compiled through the system. Facebook says over one billion of those photos will be deleted, although the company will keep DeepFace, the advanced algorithm that powers the facial recognition system.
Facebook has announced they will be deleting over a billion face recognition templates as they shut down their entire face recognition system. This is great news for Facebook users, and for the global movement pushing back on this technology. https://t.co/0ErdCBhkCT
In a blog post, Jerome Presenti, the vice president of artificial intelligence at Meta—the new name of Facebook’s parent company following a rebranding last week that was widely condemned as a ploy to distract from recent damning whistleblower revelations—described the policy change as “one of the largest shifts in facial recognition usage in the technology’s history.”
“The many specific instances where facial recognition can be helpful need to be weighed against growing concerns about the use of this technology as a whole,” he wrote.
Facial recognition technology, which has advanced in accuracy and power in recent years, has increasingly been the focus of debate because of how it can be misused by governments, law enforcement, and companies. In China, authorities use the capabilities to track and control the Uighurs, a largely Muslim minority. In the United States, law enforcement has turned to the software to aid policing, leading to fears of overreach and mistaken arrests.
Concerns over actual and potential misuse of facial recognition systems have prompted bans on the technology in over a dozen U.S. locales, beginning with San Francisco in 2019 and subsequently proliferating from Portland, Maine to Portland, Oregon.
Caitlin Seeley George, campaign director at Fight for the Future, was among the online privacy campaigners who welcomed Facebook’s move. In a statement, she said that “facial recognition is one of the most dangerous and politically toxic technologies ever created. Even Facebook knows that.”
"Facial recognition is one of the most dangerous and politically toxic technologies ever created. Even Facebook knows that," @caitlinseeley of @fightfortheftr told ABC News, "and even as algorithms improve, facial recognition will only be more dangerous." https://t.co/XBZGfyE6mp
— Evan Greer is on Mastodon and Bluesky (@evan_greer) November 2, 2021
Seeley George continued:
From misidentifying Black and Brown people (which has already led to wrongful arrests) to making it impossible to move through our lives without being constantly surveilled, we cannot trust governments, law enforcement, or private companies with this kind of invasive surveillance.
“Even as algorithms improve, facial recognition will only be more dangerous,” she argued. “This technology will enable authoritarian governments to target and crack down on religious minorities and political dissent; it will automate the funneling of people into prisons without making us safer; it will create new tools for stalking, abuse, and identity theft.”
Seeley George says the “only logical action” for lawmakers and companies to take is banning facial recognition.
So Facebook is deleting one billion facial recognition scans, but it's keeping DeepFace, the model that is trained on all those faces. Note that "the company has also not ruled out incorporating facial recognition into future products." Very meta. 👀 https://t.co/8ntPg5Hyf9
Amid applause for the company’s announcement, some critics took exception to Facebook’s retention of DeepFace, as well as its consideration of “potential future applications” for facial recognition technology.
Originally published on Common Dreams by BRETT WILKINS and republished under a Creative Commons license (CC BY-NC-ND 3.0)
Here we go again, another end of the month nears and that means some movies on Netflix have to go in order to make way for new content. There are tons of brand new Originals comings this fall, however, the time comes, when nostalgia can kick in and watching some “oldies” but goodies feels like the right move.
Especially if you aren’t into watching scary or horror films for Halloween, there are a handful of additional genres to pick from. You can watch not one but two different Leonardo DiCaprio titles before they are gone, if you are more into Sci-Fi there is “Inception” (Trailer below) or Comedy/Action in “Catch Me If You Can”.
If you rather prefer something more light-hearted for some laughs, you have some good options with Reese Witherspoon in “Legally Blonde”, Jack Black in “Tenacious D” or Matthew Broderick “Ferris Bueller’s Day Off”.
Here is the full list of Movies leaving Netflix Sunday at Midnight:
60 Days In: Season 5 Angels & Demons Battle: Los Angeles Beowulf Billy on the Street: Seasons 1-5 Catch Me If You Can The Da Vinci Code Ferris Bueller’s Day Off Forged in Fire: Season 6 The Heartbreak Kid The Impossible Inception Legally Blonde Mile 22 Norman Lear: Just Another Version of You Reckoning: Limited Series Snowden Tenacious D in The Pick of Destiny Yes Man
“Changing their name doesn’t change reality: Facebook is destroying our democracy and is the world’s leading peddler of disinformation and hate.”
Tech ethicists and branding professionals on Thursday said consumers should not be hoodwinked by Facebook’s name change, which numerous observers compared to earlier efforts by tobacco and fossil fuel companies to distract attention from their societal harms.
“Don’t be fooled. Nothing changes here. This is just a publicity stunt hatched by Facebook’s PR department to deflect attention as Zuckerberg squirms.”
Facebook co-founder and CEO Mark Zuckerberg announced the Meta rechristening during Facebook Connect, the company’s annual virtual and augmented reality conference, explaining that “we are a company that builds technology to connect people and the metaverse is the next frontier, just like social networking was when we got started.”
“Some of you might be wondering why we’re doing this right now,” he added. “The answer is that I believe that we’re put on this Earth to create. I believe that technology can make our lives better.”
Many critics found Zuckerberg’s explanation unconvincing at best and, at worst, disingenuous.
“Changing their name doesn’t change reality: Facebook is destroying our democracy and is the world’s leading peddler of disinformation and hate,” the watchdog group Real Facebook Oversight Board said in a statement. “Their meaningless name change should not distract from the investigation, regulation, and real, independent oversight needed to hold Facebook accountable.”
Us: Please stop destroying society
Facebook: Okay what if you just call us Meta now 😉
Vahid Razavi, founder of the advocacy group Ethics in Tech, told Common Dreams: “Don’t be fooled. Nothing changes here. This is just a publicity stunt hatched by Facebook’s PR department to deflect attention as Zuckerberg squirms” over the negative press from recent whistleblower revelations.
Former Facebook employees-turned whistleblowers say the company’s profit-seeking algorithms—and its executives who know their insidious impacts—are responsible for the mass dissemination of harmful content, including hate speech and political, climate, and Covid-19 misinformation.
Siva Vaidhyanathan, a media studies professor at the University of Virginia and author of the book Antisocial Media, told Time that “the Facebook of today has never been the end game for Zuckerberg.”
“He’s always wanted his company to be the operating system of our lives that can socially engineer how we live and what we know,” Vaidhyanathan continued, adding that the new name is “not going to change his vision for his company—he’s never let anybody on the outside change his mind.”
Zuckerberg, he said, “wants to take the dynamic of algorithmic guidance out of our phones and off of our computers and build that system into our lives and our consciousness, so our eyeglasses become our screens, and our hands become the mouse.”
Some observers compared Facebook’s attempt to rebrand itself to what they called similar efforts by Big Tobacco and fossil fuel corporations.
“It didn’t do anything,” Laurel Sutton, co-founder of the branding agency Catchword, toldTime. “People still knew that Altria was Philip Morris and they didn’t rehabilitate their reputation simply because they changed the name.”
“There’s no name that’s going to rehabilitate the behavior that they’ve displayed so far,” Sutton said of the social media giant. “Maybe put that time and energy into rehabilitating their morals and ethics and business decisions rather than just trying to slap a new name on something.”
Originally published on Creative Commons by BRETT WILKINS and republished under a Creative Commons License (CC BY-NC-ND 3.0)
The metaverse is a network of always-on virtual environments in which many people can interact with one another and digital objects while operating virtual representations – or avatars – of themselves. Think of a combination of immersive virtual reality, a massively multiplayer online role-playing game and the web.
The metaverse is a concept from science fiction that many people in the technology industry envision as the successor to today’s internet. It’s only a vision at this point, but technology companies like Facebook are aiming to make it the setting for many online activities, including work, play, studying and shopping.
Metaverse is a portmanteau of meta, meaning transcendent, and verse, from universe. Sci-fi novelist Neal Stephenson coined the term in his 1992 novel “Snow Crash” to describe the virtual world in which the protagonist, Hiro Protagonist, socializes, shops and vanquishes real-world enemies through his avatar. The concept predates “Snow Crash” and was popularized as “cyberspace” in William Gibson’s groundbreaking 1984 novel “Neuromancer.”
There are three key aspects of the metaverse: presence, interoperability and standardization.
Presence is the feeling of actually being in a virtual space, with virtual others. Decades of research has shown that this sense of embodiment improves the quality of online interactions. This sense of presence is achieved through virtual reality technologies such as head-mounted displays.
Interoperability means being able to seamlessly travel between virtual spaces with the same virtual assets, such as avatars and digital items. ReadyPlayerMe allows people to create an avatar that they can use in hundreds of different virtual worlds, including in Zoom meetings through apps like Animaze. Meanwhile, blockchain technologies such as cryptocurrenciesand nonfungible tokens facilitate the transfer of digital goods across virtual borders.
Standardization is what enables interoperability of platforms and services across the metaverse. As with all mass-media technologies – from the printing press to texting – common technological standards are essential for widespread adoption. International organizations such as the Open Metaverse Interoperability Group define these standards.
Why the metaverse matters
If the metaverse does become the successor to the internet, who builds it, and how, is extremely important to the future of the economy and society as a whole. Facebook is aiming to play a leading role in shaping the metaverse, in part by investing heavily in virtual reality. Facebook CEO Mark Zuckerberg explained in an interview his view that the metaverse spans non-immersive platforms like today’s social media as well as immersive 3D media technologies such as virtual reality, and that it will be for work as well as play.Hollywood has embraced the metaverse in movies like ‘Ready Player One.’
The metaverse might one day resemble the flashy fictional Oasis of Ernest Cline’s “Ready Player One,” but until then you can turn to games like Fortnite and Roblox, virtual reality social media platforms like VRChat and AltspaceVR, and virtual work environments like Immersed for a taste of the immersive and connected metaverse experience. As these siloed spaces converge and become increasingly interoperable, watch for a truly singular metaverse to emerge.
Facebook Inc. has rebranded itself, now, as Meta, most likely as a means to separate the corporate identity of the social network that has been tied to a myriad of ugly controversies. The name change is meant to highlight the company’s shift to virtual reality and the metaverse.
CEO Zuckerberg spoke at the Facebook’s Connect virtual conference and commented on the name change, “From now on, we’re going to be metaverse-first, not Facebook-first.”
The new name change does not affect the company’s share data or corporate structure, however the company will start trading under the new ticker, MVRS starting December 1.
Needless to say, Twitter comments and memes instantly rolled in after the rebrand announcement:
Facebook has named itself Meta, a word that means "please forget about all the leaked internal documents that are currently showing all the horrors of social media"
The Verge interview with Adobe’s CPO, has mega details
In a new, extensive, Verge interview podcast with Adobe’s CPO, Scott Belsky, a a ‘Prepare as NFT’ system launch for Photoshop was confirmed for the end of the month.
The idea is to maintain a kind of proof of originality system to help prevent fake NFTs (minting non-fungible tokens) from being minted and sold by imposters. The final choice is in the buyers hands at this stage, but having a way for creators to prove authenticity would be a big step.
Since this week Adobe is also holding its annual conference, called Adobe Max, there are also a bunch of new features arriving for Creative Cloud and a slew of app including Photoshop.
Big news! We've partnered up with @Adobe and @ContentAuth to enhance attribution of NFTs on Rarible. 🔎 Now collectors can see if the wallet used to design an NFT was the same one used to mint it as part of the Content Authenticity Initiative (#CAI) – https://t.co/EnWOAilv5g
Intersecting worlds collide with Adobe in them all…
Adobe has been around, amazingly, since 1982, and millions of digital creatives and content creators use their products.
Photoshop is so entrenched that it has long achieved verb status: if you want to enhance a photo, for example to enlarge your backside or smooth out your skin, just “photoshop it”. And over use is derided as a “photoshopped” persona or image.
Premiere Pro and After Effects, especially the latter, get a lot of pro and semi-pro use for video production. Many, many Pro photographers use Lightroom. The upgrade system for Adobe products and the creative cloud, such as the recent AI and neural engine assisted effects drive change and upgrades at a furious pace.
With the entire content, image and video creation industry becoming more and more vital to networked human communications, tracing and verifying authorship and authenticity are becoming more and more crucial.
Adobe is moving, with caution due to the issues that could arise, into the area on multiple fronts. As per the Verge article;
“With what Adobe is calling Content Credentials, creators will be able to link their Adobe ID with their crypto wallet and mint their work with participating NFT marketplaces. The software company says the feature should be compatible with popular NFT marketplaces including OpenSea, KnownOrigin, SuperRare, and Rarible. A ‘verified certificate’ that comes with minting an NFT with Photoshop’s Content Credentials will prove that the source of the art is authentic.”
Small businesses and individuals say that in order to sell their products online in the U.S., they have to be on Amazon and—given the millions of products on its virtual shelves at any moment—they have to get a high ranking from Amazon’s product search engine or buy sponsored listings.
Amazon transitioned from digital retailer to sales platform in 2000, when it took a page from eBay and started allowing individuals and companies to sell through its website. This led to explosive sales growth (though the company reported only small profits overall, choosing to reinvest its profits for most of its existence). Amazon encouraged these “third-party sellers” with add-on services like storage, shipping, and advertising. Third-party sellers now account for 58 percent of sales on Amazon.
Even as sellers saw their revenues grow, they started to suspect that Amazon was using their nonpublic sales information to stock and sell similar products, often for less money.
Indeed, Amazon has been investing in creating products sold under its own brand names since at least 2007. Since 2017, it has dramatically expanded its catalog of private-label brands (which are trademarked by Amazon and its partners) and its list of exclusive products (developed by third-party companies who agree to sell them only on Amazon). The company refers to both as “our brands” in various parts of its website.
We found that Amazon has now registered trademarks for more than 150 private-label brands, and market research firm TJI Research estimated the number of brands developed by others but sold exclusively on Amazon.com at 598 in 2019. Some of its house brand names signal to buyers that they are part of the company—such as Amazon Basics, Amazon Essentials, and Amazon Commercial.
But hundreds of others carry labels that do not clearly indicate that they belong to the online retail giant—including Goodthreads, Lark & Ro, Austin Mill, Whole Paws, Afterthought, Truity, find., Fetch, Mr. Beams, Happy Belly, Mama Bear, Wag, Solimo, and The Portland Plaid Co.
Amazon says it sold $3 billion in private-label goods in 2019, representing just one percent of sales on the platform, but does not specify which brands are included in that estimate. Analysts with SunTrust Robinson Humphrey estimated that Amazon sold five times as much, $15.6 billion of private-label goods in 2019, including brands owned by Whole Foods, and that the figure will reach $31 billion by 2022.
The result is that sellers now not only compete against each other for placement in Amazon search results but also increasingly against Amazon’s own in-house brands and exclusives. According to a to a 2021 report by JungleScout, 50 percent of sellers say Amazon’s products directly compete with theirs.
We sought to investigate how Amazon treats its own products in search results. These are proprietary devices, private labels, and exclusive-to-Amazon brands it considers “our brands.”
To do so, we started by developing a list of 3,492 popular product searches, ran those searches on desktop (without logging in), and analyzed the first page of results.
We found that in searches that contained Amazon brand and exclusive products, the company routinely put them first, above those from competing brands with better ratings and more reviews on Amazon.
Furthermore, we trained supervised machine learning classifiers and found that being an Amazon brand or exclusive was a significantly more important factor in being selected by Amazon for the number one spot than star ratings (a proxy for quality), review quantity (a proxy for sales volume), and any of the other four factors we tested. We did not analyze the potential effect of price on ranking because unit sizes were not standard, affecting price. In addition, similar products can vary by factors that affect price, such as materials and workmanship, for which we also could not control.
Importantly, we found that knowing only whether a product was an Amazon brand or not could predict whether the product got the top spot 70 percent of the time.
In a nationally representative survey we commissioned, only 17 percent of respondents said they expect the determining factor behind whether Amazon places a product first is whether it owns the brand. About half (49 percent) said they thought the products Amazon placed in the number one spot were the best-selling, best-rated, or had the lowest price. The remaining 33 percent said they didn’t know how Amazon ranked products.
We found that Amazon disproportionately placed its own products in the top search result. Despite making up only 5.8 percent of products in our sample, Amazon gave its own products and exclusives the number one spot 19.5 percent of the time overall. By comparison, competing brands (those that are not Amazon brands or exclusive products) were given the number one spot at a nearly identical rate but comprised more than 13 times as many products at 76.9 percent.
Most of the Amazon brand and exclusive products that the company put in the number one spot, but not all—83.9 percent—were labeled “featured from our brands” and carried the phrase “sponsored result” in the source code (as well as being part of a grid labeled “search results” in the source code). They were not marked “sponsored” to shoppers.
In a short, written statement, Amazon spokesperson Nell Rona said that the company does not favor its brands in search results and that it considers “featured from our brands” listings as “merchandising placements” and not “search results,” despite their presence in the search results grid. Rona said these listings are not advertisements, and declined to answer dozens of other questions.
Overall, 37.4 percent of Amazon brand or exclusive products in search results in our sample were neither labeled as “our brands” nor carried a name widely associated with the company, such as AmazonBasics or Whole Foods. That left buyers unaware that they were buying an Amazon brand or exclusive-to-Amazon product.
Nearly nine-in-10 U.S. adults who responded to our survey were unable to identify Amazon’s highest-selling private label brands (Pinzon, Solimo, and Goodthreads), and only 51 percent were aware that Whole Foods is an Amazon-owned brand.
Rona said Amazon identifies its products by including the words “Amazon brand” on the products page, among a list of the item’s features, and sometimes in the listing title. We only found this to be the case in 23 percent of products in our sample that were Amazon-owned brands.
Comparing product pages three months apart, we found that they were less dynamic than they used to be. The default seller among products with multiple merchants only changed in 23.5 percent of products in our data. This was significantly less often than a comparable study from five years ago.
Background
Amazon and third-party sellers have a tense symbiosis. Amazon founder and chairman Jeff Bezos has acknowledged the importance of sellers to the company’s bottom line but also calls them competitors. Amazon provides shipping, inventory management, and other services, he wrote, that “helped independent sellers compete against our first-party business” to begin with. Sellers say Amazon’s fees cut deep into their margins but they can’t get the same volume of sales anywhere else.
Antitrust regulators in Europe, Asia, and North America have been examining Amazon’s treatment of third-party sellers.
The European Commission announced an antitrust investigation in 2019, alleging Amazon used third-party seller data to inform its own sales decisions. The commission also announced a separate investigation in 2020 into whether Amazon gives preference to its own listings and to third-party sellers that use its shipping services over other sellers. Last year, India’s antitrust regulator announced an investigation into alleged anti-competitive practices by Amazon, including preferential treatment for some sellers. And in June 2021, U.S. lawmakers introduced the American Choice and Innovation Online Act, which prohibits large platforms from advantaging themselves in their own marketplaces or using nonpublic data generated by business conducted on their platform. Authorities in Germany and Canada are investigating Amazon’s selling conditions for third-party sellers, and the attorney general for Washington, D.C., filed a lawsuit in May 2021 that accuses Amazon of overly restrictive requirements for third-party sellers.
Also last year, U.S. lawmakers pressed Bezos on his treatment of third-party sellers during a congressional hearing that was part of an antitrust investigation into the four major tech companies. Rep. Lucy McBath, a Democrat from Georgia, told Bezos, “We’ve interviewed many small businesses, and they use the words like ‘bullying,’ ‘fear,’ and ‘panic’ to describe their relationship with Amazon.” The resulting report produced by the subcommittee indicated Amazon was well aware of its power over third-party sellers, citing an internal Amazon document that “suggests the company can increase fees to third-party sellers without concern for them switching to another marketplace.”
Journalists and researchers have documented instances of Amazon promoting its house brands over competitors’. In 2016, Capitol Forum, a subscription news service focused on antitrust issues, examined hundreds of listings and found that Amazon “prioritizes its own clothing brands on the promotional carousel labeled ‘Customers Who Bought This Item Also Bought’ ” on product pages. Capitol Forum said Amazon did not respond to its request for comment.
A study titled “When the Umpire is also a Player: Bias in Private Label Product Recommendations on E-commerce Marketplaces,” presented at the Association for Computing Machinery’s Conference on Fairness, Accountability, and Transparency in March 2021, examined how Amazon’s private-label brands performed in “related products” recommendations on product pages for backpacks and batteries. The researchers said they found that “sponsored recommendations are significantly more biased toward Amazon private label products compared to organic recommendations.”
In June 2020, ProPublica reported that Amazon was reserving the top spot in search results for its own brands across dozens of search terms, labeling it “featured from our brands” and shutting others out. An Amazon spokesperson told ProPublica at the time that the move was a “normal part of retail that’s happened for decades.”
Our investigation is the first study to use thousands of search queries to test how Amazon’s house brands rank in search results—and to use machine learning classifiers to determine whether sales or quality appeared to be predictive of which products Amazon placed first in search results.
In addition, we used a multipronged approach to identify Amazon house brands and exclusives, building a data set of 137,428 unique products on Amazon, which is available in our GitHub. We were unable to find any such publicly accessible dataset when we began our investigation.
Methodology: Data Collection
Sourcing Product Search Queries
To measure how Amazon’s search engine ranked Amazon’s own products relative to competing brands, we needed a list of common queries that reflect what real people search. We built the dataset from top searches from U.S. e-commerce retailers, using two sources.
The first was autocomplete queries on Amazon.com’s and Walmart.com’s product search bars. We cycled through each letter of the alphabet (A–Z) as well as numbers ranging from 0 to 19 and saved the suggested search queries presented by the autocomplete algorithm. This process yielded 7,696 queries from Amazon.com and 3,806 queries from Walmart.com.
We then gathered the most popular searches reported by Amazon via its Seller Central hub. We collected the top 300 searches between Q1 and Q3 2020 for the Amazon categories “Softlines,” “Grocery,” “Automotive,” “Toys,” “Office Products,” “Beauty,” “Baby,” “Electronics,” and “Amazon.com.” This provided 2,700 unique searches.
Combining the autocomplete queries and seller-central queries resulted in 11,342 unique “top search” queries.
Collecting Search Results
We created a Firefox desktop emulator using Selenium. The emulator visited Amazon.com and made each of the 11,342 searches on Jan. 21, 2021. The search emulator was forwarded through IP addresses in a single location, Washington, D.C., in order to reduce variation in search results (which typically vary by location).
We saved a screenshot of the first page of search results as well as the HTML source code. (Examples of screenshots and source code for search results are available on GitHub.)
In the source code of product search result pages, Amazon titles some listings with the data field “s-search-result.” This is what we are calling search results in our data. Amazon does serve other products on the search results page in advertising and other promotional carousels, including “editorial picks” and “top rated from our brands,” but those do not appear in every result (at most a third of our sample), and they are not part of the grid that Amazon labels search results.
On desktop, the majority of Amazon-labeled “search results” in our data were delivered in uniform 60-product positions (four per column for 15 rows, though Amazon narrows the width to three columns on smaller screens). Some searches returned fewer than 60 products, but none returned more. A minority (about one in 10) of searches in our data returned 22 products or fewer, delivered in a single column, one item per row. This happened for some electronics searches but never in other search categories.
Because we were seeking to analyze how Amazon ranks its own products relative to competing brands’ products, we further limited our analysis to search results that contained Amazon brands and exclusives on the first page. Of the 11,342 top searches, slightly less than three in 10 (30.8 percent) contained this type of product on the first page. We used the resulting 3,492 top searches for our analysis.
Identifying Amazon’s Brands and Exclusives
We were unable to find a public database of Amazon brand and exclusive products, so we had to build one.
We started with the search pages themselves. On many (but not all), Amazon provides a filter on the left-hand side, allowing shoppers to limit the search to “our brands,” which Amazon says lists only its private label products and “a curated selection of brands exclusively sold on Amazon.”
We collected each of those “our brand” results for each query, saving a screenshot and the source code, also on Jan. 21, 2021.
We then discovered an undocumented API that yields all Amazon “our brands” products for any given search. We ran all 11,342 search terms through this API and saved those responses as well. (API responses are available on GitHub.)
Both the search emulator and API requests were forwarded through IP addresses in Washington, D.C.
Strangely, Amazon does not identify proprietary electronics, including Kindle readers and Ring doorbells, when a shopper filters a search result to list only Amazon’s “our brands.” To identify those, we also gathered products Amazon listed as best sellers in the category “Amazon Devices & Accessories.”
Together, all three sources yielded a dataset of 137,428 unique products, identified by their 10-character ASIN (Amazon Standard Identification Number). This dataset of Amazon’s proprietary devices, private label, and exclusive products is available on GitHub.
It is the largest and most comprehensive open access dataset of Amazon brand and Amazon-exclusive products we’ve seen, and yet we know it is not complete. Amazon told Congress in July 2019 that at that time it sold approximately 158,000 products from its own brands.
Collecting Product Pages
In addition to the above, we collected the individual product pages for the 125,769 products that appeared in the first page of our 3,492 top searches in order to analyze the buy box information. The buy box displays the price, return policy, default seller, and default shipper for a product.
To gather the product pages, we used Amazon Web Services and the same Selenium emulator we made for collecting the search result pages. The emulator visited the hyperlink for each product and saved a screenshot and the source code.
We collected these pages on Feb. 3–6 and Feb. 17–18, a few weeks after we scraped the search result pages. To determine the effects of the delay, we analyzed how often a subsample of buy boxes’ default sellers and shippers flipped between Amazon and third parties after a similar lag and found they remained largely unchanged (see more in Limitations).
Product Characteristics
We asked up to four questions of every product listing in order to identify certain characteristics and used this to produce the categories we used in our analysis.
is_sponsored: Is the listing a paid placement?
is_amazon: Is the listing for an Amazon brand or exclusive?
is_shipped_by_amazon: Does the default seller of the product (the “buy box”) use Amazon to ship the listed product?
is_sold_by_amazon: Is the default seller of the product Amazon?
Sponsored products (is_sponsored) are the most straightforward: Amazon labels them “sponsored.” If a product in the Amazon-labeled search results is not sponsored, we consider it “organic.” We only identified products with subsequent features if they were organic.
We identified an organic product as an Amazon brand or exclusive (is_amazon) when it matched one of the 137,428 Amazon ASINs we collected. If it didn’t match, we considered it a “competing brand.”
We identified a product as is_amazon_sold if the “sold by” text in the buy box contained “Amazon,” “Whole Foods,” or “Zappos” (which is owned by Amazon). If it didn’t, we identified the product as “Third-Party Sold.”
We identified a product as is_amazon_shipped if the buy box shipper information contained “Amazon” (including “Amazon Prime,” “Amazon Fresh,” and “Fulfilled by Amazon”), “Whole Foods,” or “Zappos” (which is owned by Amazon). If it didn’t contain Amazon, we identified products as “Third-Party Shipped.”
We use these features to train and evaluate predictive classifiers (see Random Forest Analysis) as well as produce product categories in our ranking analysis (see the following section).
Most of the categories have a direct relationship with the features they are named after.
We categorized products as “Sponsored” if we identified them as is_sponsored. Similarly, we categorized products as “Amazon Brands” and exclusives if they are organic and is_amazon, and “Competing Brands” if the products are organic and not is_amazon.
We categorized organic products as entirely “Unaffiliated” if they did not meet the criteria for is_amazon, is_amazon_sold, and is_amazon_shipped. In other words, these are competing brands that are sold and shipped by third-party sellers.
The features and categories we identified are hierarchical and overlap. Their relationships are summarized in the diagram below.
Data Analysis
Ranking Analysis: Who Comes Out on Top?
We analyzed the rate of products that received the top search result relative to the proportion of products of the same category that appeared in our sample. We found that Amazon brands and exclusives were disproportionately given the number one search result relative to their small proportion among all products.
We used two straightforward measures for our analysis. First, we calculated a population metric using the percentage of products belonging to each category among products from all the search pages. To do this, we divided the number of products per category that occupy search result slots compared to all product slots in our sample. This included duplicates.
We then calculated an incidence rate for how frequently Amazon gave products in each category the coveted first spot in search results. We did this by dividing the number of searches in each category in the top spot by the total number of searches in our sample (with at least one product). (A table of each of these metrics by category appears in our GitHub and in “Supplementary datasets.”)
We chose to focus on that top left spot because Amazon changes the number of items across the first row based on screen size, and some searches return only a single item per row, so the top left spot is the only one to remain the same across all search results in our data.
In a majority of the searches in our data, 59.7 percent, Amazon sold the top spot to a sponsored product (17.3 percent of all product slots). The bulk of our analysis concerns the remaining 40.3 percent.
When we looked at all searches, Amazon gave its own products the number one spot 19.5 percent of the time even though this category made up only 5.8 percent of products in our sample.
Amazon gave competing brands the number one spot at a nearly identical rate (20.8 percent of the time), but these cover more than 13 times the proportion of products in our sample (76.9 percent).
Amazon gave entirely unaffiliated products (competing brands that were sold and shipped by third-party sellers) the top spot 4.2 percent of the time, but these products made up 5.8 percent of all products in our sample.
The only organic (nonsponsored) category that Amazon placed in the number one spot at a rate that was greater than the proportion of its products in the sample was its own brands and exclusives.
About eight in 10 (83.9 percent) of the Amazon brands or exclusives that Amazon placed in the top spot were labeled “featured from our brands.” These are identified as part of Amazon’s “search results” and are not marked “sponsored.” However, the source code for those labeled results contained information that was the same as sponsored product listings (data-component-type=”sp-sponsored-result”). These Amazon brand and exclusive brand products were not labeled as “sponsored” for shoppers.
Where Are Products Placed?
In addition to the top spot, we calculated how often Amazon placed each type of product in each search result position down the page (1–60). All searches have a number one spot but do not always return 60 results, so we always calculated this rate using the number of searches with that product spot as the denominator. Sponsored results that are part of search results are counted in the denominator of the rates.
(As mentioned earlier, we did not include promotional and advertising carousels and modules because these are not part of the grid labeled “search results” in the metadata and none appeared in the same place in a majority of search results.)
Amazon placed its own products and exclusives in the number one spot 3.5 times more frequently than in any other position on the search page.
It placed competing brands (including those it sells itself) everywhere except the top (1) and bottom (15) rows of the search page. Competing brands appeared only sparsely where sponsored products were common in search results (rows 4–5 and 8–9). The company placed entirely unaffiliated products—meaning a competitor’s brand that was both sold and shipped by a third party—primarily in the lower rows (9–13).
In 59.7 percent of searches in our sample, Amazon gave the number one spot to sponsored products. When Amazon returned a 15th row, it always listed sponsored products there, too.
Not Always Labeled
Amazon only identified 42 percent of its brands and exclusives to the shopper with a disclosure label (e.g., “featured from our brands,” “Amazon brand,” or “Amazon exclusive”). Of the Amazon brand and exclusive products in our sample, 28.8 percent were from a brand many people (but not all) would understand to be a private Amazon label, such as “Whole Foods,” “Amazon Basics,” or “Amazon Essentials.” Some were both labeled and from a better-known Amazon brand. For the remaining 37.4 percent, we found that buyers were not informed that they would be purchasing an Amazon brand or exclusive.
When the same product that is an Amazon brand or exclusive appeared more than once in the same search, we considered it labeled if any of the listings were labeled. This gives Amazon the benefit of the doubt by assuming that a customer will understand that the disclaimer applies to duplicate listings. Therefore, our metrics for disclosure are the lower bound.
Duplicates
Amazon gave its own products more than one spot in search results in roughly one in 10 (9.2 percent of) searches, not including other potential duplicates in promotional carousels. It did not give competing brands’ products more than one spot for organic search results.
Survey Results
We commissioned the market research group YouGov to conduct a nationally representative survey of 1,000 U.S. adults on the internet, to contextualize our findings. It revealed that 76 percent of respondents correctly identified Amazon Basics as being owned by Amazon and 51 percent correctly identified Whole Foods.
The vast majority of respondents, however, could not identify the company’s top-selling house brands that did not contain the words “Amazon” or “Whole Foods” in their name. Ninety percent did not recognize Solimo as an Amazon brand, and 89 percent did not know Goodthreads is owned by Amazon. Other top-selling brands, like Daily Ritual, Lark & Ro, and Pinzon were not recognized by 94 percent of respondents as Amazon brands.
We also asked respondents what trait defines the top-ranked products in Amazon search results. Few expected it to be based solely on being an Amazon brand. More than 21 percent of respondents thought the top-ranked product would be “the best seller,” 17 percent thought it was “the best rated,” 11 percent thought it was “the lowest price,” and 33 percent of respondents were “not sure.” Only 17 percent thought the number one listed item was “a product from one of Amazon’s brands.”
Quality and Sales Factors
We compared the star ratings (a rough proxy for quality) and number of reviews (a rough proxy for sales volume) of the Amazon Brands that the company placed in the number one spot on the product search results page with other products on the same page.
We found that in two-thirds (65.3 percent) of the instances where Amazon placed its own products before competitor brands, the products that were Amazon brands and exclusives had lower star ratings than competing brands placed lower in the search results. Half of the time (51.7 percent) that the company placed its own products first, these items had fewer reviews than competing products the company chose to place lower on the search results page.
One in four (28.0 percent of) top-placed Amazon brands had both lower star ratings and fewer reviews than products from competing brands on the same page.
When we evaluated several predictive models, we found that features like star ratings and the number of reviews were not the most predictive features among products Amazon placed in the number one spot.
Random Forest Analysis
We tried to determine which features differentiate the first organic product on search results from the second organic product on the same page.
To do this, we created a categorical dataset of product comparisons and used it to train and evaluate several random forest models.
The product comparisons looked at differences in features that we had access to, and that seemed relevant to product rankings (like stars and reviews). We found that being an Amazon brand or exclusive was by far the most important feature, of the seven we tested, in Amazon’s decision to place a product in the number one versus number two spot in product search results.
How We Created Product Comparisons
We took our original dataset of 3,492 search results with at least one Amazon brand or exclusive, filtered out sponsored products, and generated a dataset of product comparisons. Each product comparison is between the number one product and number two product on the same search page. The random forest used these attributes to predict a yes or no (boolean) category: which product among the pair was given the top search result (placed_higher).
The product comparisons encode the differences in star ratings (stars_delta) and number of reviews (reviews_delta); whether the product appeared among the top three clicked products from one million popular searches in 2020 from Amazon Seller Central (is_top_clicked); and whether the product was sold by Amazon (is_amazon_sold), shipped by Amazon (is_amazon_shipped), or was an Amazon brand or exclusive (is_amazon). We also used a randomly generated number as a control (random_noise). Distributions of each of these features is available on GitHub.
While we had access to price information, we did not analyze its potential effect on ranking because price was not standardized per unit. We also had access to each product’s “best sellers rank” for the time period we collected product pages, but the same product could have various different rankings in different Amazon categories (e.g., #214 in Beauty & Personal Care and #3 in Bath Salts), making consistent comparisons impossible.
This produced a dataset of 1,415 product comparisons. (To see exactly how we created our training and validation dataset, see our GitHub.)
By creating this dataset of product comparisons, we were able to compare two products with one model and control for which features led to higher placement.
Why Random Forest?
A random forest combines many decision tree models, a technique we used in a previous Markup investigation into Allstate’s price increases. Decision trees work well at predicting categories with mixed data types, like those from our product comparisons.
Decision trees can, however, memorize or “overfit” the training data. When this happens, models can’t make good predictions on new data. Random forests are robust against overfitting and work by training a forest full of decision trees with random subsets of the data. The forest makes predictions by having each tree vote.
We used grid search with five-fold cross-validation to determine optimal hyperparameters (parameters we control versus those that arise from learning cycles): 500 decision trees in each forest, and a maximum of three questions each decision tree can ask the data. By asking more questions, each tree becomes deeper. But that also means that the trees are more likely to memorize the data. The more trees we train, the more resources it takes to run our experiment. Grid search trains and evaluates models with an exhaustive list of combinations of these hyperparameters to determine the best configuration.
Evaluating the Models
Our model correctly picked Amazon’s number-one-ranked product 73.2 percent of the time when all seven features were considered.
We systematically removed each feature and retrained and reevaluated the model (called an ablation study) in order to isolate the importance of each individual feature. We used the accuracy of the model trained on all seven features as a baseline to compare each newly evaluated model (see results in Change of Accuracy in table above).
When we did this, we saw that removing information about whether a product was an Amazon brand or exclusive (is_amazon) reduced the model’s ability to pick the right product by 9.7 percentage points (to 63.5 percent). This drop in performance was far greater than any other individual feature, suggesting that being an Amazon brand or exclusive was the most predictive feature among those we tested in determining which products Amazon placed in the first organic spot of search results.
To demonstrate the influence of Amazon brands and exclusives in another way, we trained a model with only is_amazon, and it correctly predicted the number one product 70.7 percent of the time. Every other standalone feature performed significantly worse, only picking the correct product between 49.3 (random_noise) and 61.5 (is_sold_by_amazon) percent of the time.
To a lesser extent, the number of reviews (reviews_delta) were also predictive of a product getting the number one spot. Removing this feature reduced the model’s performance by 3.3 percentage points.
The other six features were less informative when it came to getting the number one spot versus the number two spot. Performance of the random forest for every possible permutation of features is available in our GitHub.
These findings were consistent with ranking the feature importance from the random forest model trained on all features. This third approach also suggests that is_amazon is the most predictive feature for the random forest.
When we compared additional product pairs with the number one spot and those of lower-ranked products beyond just the number two spot, is_amazon remained the most predictive feature out of those we tested (results in our GitHub).
We used predictive models to show that being an Amazon brand or exclusive was the most influential feature among those we tested in determining which products Amazon chose to place at the top of search results.
Limitations
Search Data Limitations
The two datasets we created are small in comparison to the full catalog of products for sale on Amazon.com, for which there are no reliable estimates. However, we sought to examine searches and products that generate significant sales, not every product or every search.
We collected search data on desktop, so our analysis only applies to desktop searches. Amazon’s search results may differ on mobile, desktop, and the Amazon app.
Amazon’s search results can also vary by location. One example is the distance of the closest Whole Foods store and its inventory, which would affect any given person’s search for certain items. We collected the data using I.P. addresses in Washington, D.C., so our results are specific to that city.
And, according to an Amazon-authored report for IEEE Internet Computing, a journal published by a division of the Institute of Electrical and Electronics Engineers, Amazon personalizes offerings to buyers according to similar items they have already purchased or rated (called item-to-item collaborative filtering). Our searches were not made in the same session nor were we logged into an Amazon account with user history, so our results were not personalized. In the absence of personalization, Amazon defaults to “generally popular items.” This also means that we did not capture search results or product pages for Amazon Prime subscribers.
Product Page Data Limitations
Some products that compete with Amazon brand and exclusive products are sold by numerous sellers, including Amazon itself. A 2016 ProPublica investigation revealed that of a sample of 250 products, Amazon took the buy box for itself or gave it to vendors that paid for the “Fulfilled by Amazon” program in 75 percent of cases. The same year, researchers at Northeastern University tracked 1,000 best-selling products over six weeks and found that buy box winners changed for seven out of 10 products in their study.
For our main analysis, we did not seek to analyze which specific seller won the buy box but rather whether the seller or shipper during our snapshot was Amazon or a third party.
We captured product pages and their subsequent buy boxes in a snapshot of time between Feb. 3–6 and 17–18. Due to a technical problem, there was a two- to four-week delay between when we collected the searches and when we collected the product pages. This means that the seller and shipper of those products are only representative of searches made during that time and could have changed from the time we collected the searches to when we collected the product pages.
When we collected product pages in February, about 3.9 percent of them were no longer available or the product had been removed from the Amazon Marketplace altogether since we gathered the search pages in January. We removed these products from any calculations involving the seller or shipper.
To test the reliability of our product page data, we took a random sample, on May 13, 2021, of 2,500 of the 125,769 products we had collected in February 2021 and reran the product page scraper.
Some of the product pages were missing data: 6.1 percent were sold out, 1.6 percent were removed from Amazon’s marketplace, and another 3.4 percent no longer displayed a default seller who won the buy box. In these latter cases, Amazon provided a button to “See All Buying Options.” The missing data did not overall favor or disfavor Amazon but rather was consistent with the proportion of Amazon-sold products (30.2 compared to 27.1 percent) from the sample of products we recollected.
The remaining 2,103 products that had legible buy boxes (the vast majority) were largely unchanged. Only 16.1 percent of products changed default sellers. This included changes between Amazon and third-party sellers.
Product sellers changed from a third party to Amazon in 1.6 ± 0.5 percent of products, and from Amazon to a third party in 3.1 ± 0.7 percent of products (margins of error calculated with 95 percent confidence).
When it came to who shipped the product, the shipper went from a third party to Amazon in 2.9 ± 0.7 percent of products, and from Amazon to a third party in 6.6 ± 1.1 percent of products.
Because the buy box remained largely unchanged during a 12-week gap in this representative subsample of our data, we find that our buy box findings are reliable, despite the three- to four-week gap between when we gathered search results and product pages.
This seemed to signal a change from previous research. So we went further to determine whether the buy box had become more stable since the 2016 Northeastern University study. That study was limited to products with multiple sellers. When we did the same, it brought the sample size down to 1,209. Looking only at products with multiple sellers, we found Amazon changed the buy box seller for only 23.5 percent of products. In addition, among products with multiple sellers, Amazon gave itself the buy box for 40.0 percent of them.
For products with multiple sellers, the winning sellers changed from Amazon to a third party in 2.1 ± 0.8 percent of products and from a third party to Amazon in 4.4 ± 1.1 percent of products. Third-party sellers changed among themselves in 31.4 percent of products sold by third-party sellers. No individual third-party seller won more than 0.06 percent of the products with more than one seller.
Shippers changed from Amazon to a third-party in 2.3 ± 0.8 percent of products and from a third party to Amazon in 7.8 ± 1.5 percent of products.
Reviewing the product pages three months apart, we found that the default seller Amazon chose for the buy box when multiple merchants were available has become significantly less likely to change from five years ago.
Limitations Identifying Amazon Brands and Exclusive Products
Amazon’s “our brands” filter is incomplete. For instance, it listed only 70.3 percent of products that were tagged “featured from our brands” on the search page. In addition, Amazon did not include its proprietary electronics in the “our brands” filtered results when we gathered the data. The company declined to answer questions about why these were not included.
Because of this, we had to use three methods to collect our product database of Amazon brands and exclusives, and it’s possible we missed some products, particularly proprietary electronics.
Black Box Audit
Our investigation is a black box audit. We do not have access to Amazon’s source code or the data that powers Amazon’s search engine. There are likely factors Amazon uses in its ranking algorithm to which we do not have access, including return rates, click-through rates, and sales. We have some data from Amazon’s Seller Central hub about popular products and clicks, but this data is itself limited and did not cover all of the products in our searches.
For these reasons, our investigation focuses on available and clear metrics: how high categories of products are placed compared to their proportion of results, how well users review highly ranked products relative to other products, and how many reviews a product has garnered, which is a crude indication of sales.
Amazon’s Response
Amazon did not take issue with our analysis or data collection and declined to answer dozens of specific questions.
In a short, prepared statement sent via email, spokesperson Nell Rona said that the company considers “featured from our brands” listings as “merchandising placements,” and as such, the company does not consider them “search results.” Rona said these listings are not advertisements, which by law would need to be disclosed to shoppers. We found these listings were identified as “sponsored” in the source code and also part of a grid marked “search results” in the source code.
“We do not favor our store brand products through search,” Rona wrote.
“These merchandising placements are optimized for a customer’s experience and are shown based on a variety of signals,” Rona said. None of these were explained beyond “relevance to the customer’s shopping query.”
Regarding disclosing to customers about Amazon brands, Rona said they are identified as “Amazon brand” on the products page, and some carry that wording in the listing. We found this to be the case in only 23 percent of products that were Amazon-owned brands.
She said brands that are exclusive to Amazon would not carry that wording since they are not owned by Amazon.
Rona supplied a link to an Amazon blog post that mentions that its branded products made up about one percent of sales volume for physical goods and $3 billion of sales revenue in 2019. It is unclear whether brands exclusive to Amazon are included in those figures.
Conclusion
Our investigation revealed that Amazon gives its own products preference in the number one spot in search results even when competitors have more reviews and better star ratings. We also found that reviews and ratings were significantly less predictive of whether a product would get the number one spot than being an Amazon brand or exclusive.
In addition, we found that Amazon placed its own products and exclusives in the top spot in higher proportion than it appeared in the sample, a preference that did not exist for any other category. In fact, it placed its own brands and exclusives in the top spot as often as competing brands—about 20 percent of the time—although the former made up only six percent of the sample and the latter 77 percent.
Almost four in 10 products that we identified as Amazon brands and exclusives in our sample were neither clearly labeled as an Amazon brand nor carried a name that most people recognize as an Amazon-owned brand, such as Whole Foods. In our survey, almost nine-in-10 U.S. adults did not recognize five of Amazon’s largest brands.
We also found that the default seller among products with multiple merchants changed for just three in 10 products over three months, a significantly lower rate of change than a similar study found five years ago.
Amazon’s dominance in online sales—40 percent in the United States—means the effect of giving its own products preference on the search results page is potentially massive, both for its own business as well as the small businesses that seek to earn a living on its platform.
Appendix
Supplementary Search Dataset and Analysis
When first exploring this topic and before hitting on our top searches dataset, we had created a generic dataset that returned similar findings. We replaced it as the main dataset because our top searches dataset was closer to real searches made by users. We include it here as a secondary dataset.
Generic Searches
We created a search dataset from products listed in each of the 18 departments found on Amazon’s “Explore Our Brands” page.
Three annotators looked through 1,626 products listed on those pages and generated between one and three search queries a person might use if searching for that product. These were meant to represent generic searches for which we know Amazon brands are competing against others.
We generated 2,558 search terms. We randomly sampled 1,600 and collected these searches using the same method and during the same time period we used to collect top searches. A quarter of the search results (24 percent) did not contain Amazon Brands, so we discarded them, leaving 1,217 generic searches, our supplementary dataset.
Generic Search Findings
In the generic searches, Amazon Brands constituted a slightly larger percentage of the overall product sample (8.2) than our top searches database (5.8). The percentage of the time Amazon gave its own products the number one spot also increased, to roughly one in four of our generic searches from one in five for our top searches.
Competing brands constituted a similar proportion of products in both of our datasets. However, Amazon placed competing brands in the number one spot even less often (10.8) in these generic searches than it had for top searches (20.8).
Entirely unaffiliated products made up even less of the pool of products in our generic searches (3.0) than top searches (5.8), and Amazon also gave them the top spot even less frequently, 1.5 percent of the time compared to 4.2 percent for top searches.
The results from this additional dataset show a similar pattern to our main dataset, whereby Amazon prioritizes its own products at the top of search results.
Counting Carousels
As mentioned earlier, we did not include sponsored or promotional carousels in our analysis.
If we were to consider sponsored or promotional carousels, the percentage of organic products from top searches would drop from 87 to 68 percent. This also means that sponsored products would increase from 17 percent to 32 percent. There were a total of 49,686 products in these carousels.
Acknowledgements
We thank Christo Wilson of Northeastern University, Juozas “Joe” Kaziukėnas of Marketplace Pulse, Rebecca Goldin of Sense About Science and George Mason University, Kyunghyun Cho of New York University, and Michael Ekstrand of Boise State University for reviewing all or parts of our methodology. We also thank Brendan Nyhan of Dartmouth College for reviewing our survey design.
Scammers Are Using Fake Job Ads to Steal People’s Identities
It has become a ubiquitous internet ad, with versions popping up everywhere from Facebook and LinkedIn to smaller sites like Jobvertise: Airport shuttle driver wanted, it says, offering a job that involves picking up passengers for 35 hours a week at an appealing weekly pay rate that works out to more than $100,000 a year.
But airports aren’t really dangling six-figure salaries for shuttle drivers amid some sudden resurgence in air travel. Instead, the ads are cybercriminals’ latest attempt to steal people’s identities and use them to commit fraud, according to recent warnings from the FBI, the Federal Trade Commission and cybersecurity firms that monitor such threats. The U.S. Secret Service, which investigates financial crimes, also confirmed that it has seen a “marked increase” in sham job ads seeking to steal people’s personal data, often with the aim of filing bogus unemployment insurance claims.
“These fraudsters, they’re like a virus. They continue to mutate,” said Haywood Talcove, chief executive of the government division of LexisNexis Risk Solutions, one of several contractors helping state and federal agencies combat identity theft. (ProPublica subscribes to public records databases provided by LexisNexis.)
ProPublica is a Pulitzer Prize-winning investigative newsroom. Sign up for The Big Story newsletter to receive stories like this one in your inbox.
This particular mutation is an emerging threat, Talcove and others said. The numbers are small so far, but they’re rapidly increasing. In March, LexisNexis detected around 2,900 ads touting unusually generous pay, using suspicious email domains and requiring that one verify one’s identity upfront. The total had grown to 18,400 by July, and then to 36,350 as of this month. Talcove said these figures are based on a small sample of job ads and that the real number is likely much higher.
This form of scam is surging at a moment when targets for job application fraud abound. Millions of Americans are quitting jobs and looking for new ones. An all-time high percentage of workers — 2.9% — quit their jobs in August, according to the U.S. Department of Labor. Meanwhile, huge numbers of laid-off workers are still looking for work, making for a historic churn in the labor market.
The ads reflect a tactical adjustment by cybercriminals. A massive wave of unemployment insurance fraud during the pandemic prompted authorities to heighten identity verification requirements. In most U.S. states, cybercriminals can no longer simply input stolen identity information into government websites and frequently collect unemployment insurance aid. Now, applicants whose names are used to apply for unemployment benefits often need to verify on their phones that they’re the ones seeking assistance, a process similar to two-factor authentication.
That means scammers may need help from their victims — and sometimes they go to elaborate lengths to mislead them. Some fraudsters recreate companies’ hiring websites. One fake job application site uses Spirit Airlines’ photos, text, font and color code. The phony site asks applicants to upload a copy of both sides of their driver’s license at the outset of the process and sends them an email seeking more information from a web address that resembles Spirit’s, with an extra “i” (spiiritairline.com). Spirit Airlines did not respond to requests seeking comment.
Other job scams are less elaborate and have more visible signs of inauthenticity. One fake ad for airport shuttle drivers on Facebook was posted by a woman who purported to be working at Denver International Airport. Diligent readers may have noticed that the only location linked from the woman’s Facebook profile was a Nigerian city called Owerri. (A spokesperson for the Denver airport reported the profile to Facebook after an inquiry by ProPublica, and the ad is no longer active.)
In other instances, unsolicited job offers simply land in applicants’ inboxes after they’ve uploaded their résumés to real job search sites, which scammers can access if they pose as potential employers. Jeri-Sue Barron has received a slew of emails since the start of the pandemic informing her that she was preapproved for a variety of jobs she hadn’t even applied for. Barron, a retiree in suburban Dallas, had uploaded her résumé to several job hunting sites in hope of finding some part-time work to supplement her Social Security income. She then received multiple job offers with nary a request for an interview. One email originated from a school in India’s Kerala state; another came from a Croatian website she’d never heard of. “They started coming in from places that were weird,” said Barron. “You almost don’t want to find out the next stage.” She ignored the offers.
As with fake unemployment claims more broadly, the fraud is being facilitated by an underground infrastructure, including online forums where cybercriminals share advice on how to perfect their techniques. A person using the handle “cleverinformation” on a U.K. forum called Carder put together a how-to video that recommends posting fake job ads using a generic job application that can be modified to collect personal data. In September, someone going by “mrdudemanguy” on another forum, known as Dread, offered this advice to a person seeking stolen identities: “Pretend to be a local business and post some job ads. When they send in their résumé, call them and ask some basic job application questions. Make them think they’ve got the job as long as they can do a background check. For the background check request they send you photos or scans of ID documents.”
In response to a query from ProPublica, mrdudemanguy did not answer questions about sharing fake ads and instead focused on explaining the source of his recommended technique and its success. “I have not tried this method myself,” he wrote. “It’s just a method that I know other people do and it does work. It can be done in any part of the world, the country does not matter. As long as the job ad looks legitimate, a person looking for a job will be likely to apply.” Questions sent to cleverinformation yielded a similar response. “It’s effective,” the person said, noting that it’s an underused technique. The person added: “Trying to start a group chat where we share our knowledge.”
The ubiquitous ad for airport shuttle drivers was discussed in a similar forum. One version of it was posted in a Telegram channel of a Nigerian scam group called Yahoo Boys Community, along with instructions on what to tell applicants to get them to share their Social Security number, photographs of their driver’s license and other personal details. The post urged the group’s 5,000 members to ask applicants generic questions via email and offer them the gig — but only if they first shared their personal documents to land the plum job. “Once the client gives you the details, buzz me on WhatsApp and let start work on it Asap,” read the July message, whose initiator could not be identified.
Job application scams have been around in various forms for years. Some entice applicants to buy equipment or software from the scammers in preparation for a nonexistent job. Others try to trick victims into working for free or reshipping goods bought with stolen credit cards. But, according to law enforcement agencies, using fake job ads to steal identities and using them to cash in on government benefits is a new wrinkle.
Alexandra Mateus Vásquez fell for one such scam in December 2020. An aspiring painter, Vásquez was thinking of quitting her sales job at a suburban mall near New York City. She applied for a graphic designer position at the restaurant chain Steak ‘n Shake via the widely used job website Indeed. She was elated when what appeared to be a Steak ‘n Shake representative invited her via Gmail to participate in an email screening test for the job.
Conducting an interview via email initially struck Vásquez as odd, but she proceeded because the questions seemed standard. They included queries like “How do you meet tough deadlines?” according to emails she shared with ProPublica, and she provided earnest answers. Hours later she received an email offering her the job and asking for her address and phone number so a formal offer letter could be dispatched. The offered pay was attractive: $30 per hour. When the letter arrived, it sought her Social Security number, too. Vásquez provided all the requested information.
Soon Vásquez was invited for a background check, via online chat, with a supposed hiring manager. She found herself trading messages with an account that had a blurry photograph of an old man and the name “Iran Coleman” attached to it. (Several other applicants described similar experiences in a discussion about the Steak ‘n Shake job on the hiring site Glassdoor.)
The person claiming to be the Steak ‘n Shake’s hiring manager requested copies of Vásquez’s personal records to verify her identity. She shared photographs of her New York state ID and her green card but grew suspicious when the person asked for her credit card number, too. As Vásquez hesitated, she got a call from ID.me, an identity verification vendor used by 27 states to safeguard their unemployment insurance programs. The company asked if she was applying for jobless aid in California. That’s when she realized she was being scammed. “I was so disappointed,” Vásquez said. “I really believed that that position was real.”
Steak ‘n Shake did not respond to messages seeking comment. (ProPublica was able to reach Iran Coleman, the purported Steak ‘n Shake manager cited in the scam. He said the Louisville Steak ‘n Shake he used to manage is closed and he hasn’t worked there since at least 2014. He said he hadn’t updated his cursory LinkedIn profile, which lists him as a Steak ‘n Shake restaurant manager, in years. Coleman said he now manages three Waffle House restaurants. “I feel for that person,” he said of Vásquez when informed of her experience.)
Vásquez reported the incident to the police and contacted the Social Security Administration, which informed her that it had denied multiple requests to create an account in her name. (A spokesperson for the agency said privacy laws preclude it from discussing individual cases.) She then gave up on her job search. “I started doubting if all the jobs I’m applying for are real,” she said. Vásquez recently launched a website to begin selling paintings online and still hopes to become a design professional.
Blake Hall, chief executive of ID.me, said the company has rolled out language on its systems that informs users when their identities are being used to apply for unemployment insurance benefits and warns them not to proceed if they are being offered a job. Hall said it’s ultimately up to users to heed such warnings. “We will do as much as we can to make it clear that they’ve been scammed,” he said, “but ultimately protecting somebody from themself is a really tall order.” He compared his company to a goalkeeper who also needs help from other members of the team, in this case the job websites where criminals post fake ads.
The Better Business Bureau said in an alert last month that Indeed, LinkedIn and Facebook topped the list of online platforms where users reported spotting fraudulent job advertisements that duped them.
Indeed removes tens of millions of job listings that do not meet its quality guidelines each month, according to a company spokesperson, and it declines to list employers’ jobs if they do not pass those guidelines. In July, the site published a blog post detailing how to spot scam job ads. “Indeed puts job seekers at the heart of everything we do,” the spokesperson said.
LinkedIn removed 10 fake airport shuttle job postings after they were pointed out by ProPublica. A spokesperson said that posting bogus job ads is a “clear violation” of LinkedIn’s terms of service and said the company is investing in new ways of spotting them, such as hiring more human reviewers and expanding a work-email verification system for potential employers.
Facebook took down some of the airport shuttle posts after ProPublica alerted the service, but the company did not respond to questions about its processes for spotting and removing fake ads.
In recent months, the social media platform has also been plagued with fraudulent pages masquerading as state unemployment agencies. Some states complained to the U.S. Department of Labor that Facebook was slow to act on their requests to remove such pages, according to a March email from the department to state workforce agencies disclosed under a public records request. A Department of Labor official said that in March the agency set up a new process for states to report fake unemployment insurance websites to Facebook and that “to date, Facebook has been responsive in taking down fraudulent pages” reported by states.
New ones, however, keep popping up: A fake version of California’s Employment Development Department Facebook page was live as of Oct. 12. The agency confirmed the page was not its own, and it was removed from Facebook shortly after ProPublica’s inquiry.
Even if online platforms clean up their job postings, other identity theft scams are proliferating. On Oct. 15, the FBI issued an alert warning about fake websites that cybercriminals created to resemble the state unemployment websites of Illinois, Maryland, Nevada, New Mexico and Wisconsin. Criminals use the sites to steal victims’ sensitive personal information, according to the FBI.
“This industry is rotten at its core,” said one critic, “and the clearest proof of that is what it’s doing to our children.”
Internal documents dubbed “The Facebook Papers” were published widely Monday by an international consortium of news outlets who jointly obtained the redacted materials recently made available to the U.S. Congress by company whistleblower Frances Haugen.
“It’s time for immediate action to hold the company accountable for the many harms it’s inflicted on our democracy.”
The papers were shared among 17 U.S. outlets as well as a separate group of news agencies in Europe, with all the journalists involved sharing the same publication date but performing their own reporting based on the documents.
According to the Financial Times, the “thousands of pages of leaked documents paint a damaging picture of a company that has prioritized growth” over other concerns. And the Washington Postconcluded that the choices made by founder and CEO Mark Zuckerberg, as detailed in the revelations, “led to disastrous outcomes” for the social media giant and its users.
From an overview of the documents and the reporting project by the Associated Press:
The papers themselves are redacted versions of disclosures that Haugen has made over several months to the Securities and Exchange Commission, alleging Facebook was prioritizing profits over safety and hiding its own research from investors and the public.
These complaints cover a range of topics, from its efforts to continue growing its audience, to how its platforms might harm children, to its alleged role in inciting political violence. The same redacted versions of those filings are being provided to members of Congress as part of its investigation. And that process continues as Haugen’s legal team goes through the process of redacting the SEC filings by removing the names of Facebook users and lower-level employees and turns them over to Congress.
One key revelation highlighted by the Financial Times is that Facebook has been perplexed by its own algorithms and another was that the company “fiddled while the Capitol burned” during the January 6th insurrection staged by loyalists to former President Donald Trump trying to halt the certification of last year’s election.
CNNwarned that the totality of what’s contained in the documents “may be the biggest crisis in the company’s history,” but critics have long said that at the heart of the company’s problem is the business model upon which it was built and the mentality that governs it from the top, namely Zuckerberg himself.
On Friday, following reporting based on a second former employee of the company coming forward after Haugen, Free Press Action co-CEO Jessica J. González said “the latest whistleblower revelations confirm what many of us have been sounding the alarm about for years.”
“Facebook is not fit to govern itself,” said González. “The social-media giant is already trying to minimize the value and impact of these whistleblower exposés, including Frances Haugen’s. The information these brave individuals have brought forth is of immense importance to the public and we are grateful that these and other truth-tellers are stepping up.”
While Zuckerberg has testified multiple times before Congress, González said nothing has changed. “It’s time for Congress and the Biden administration to investigate a Facebook business model that profits from spreading the most extreme hate and disinformation,” she said. “It’s time for immediate action to hold the company accountable for the many harms it’s inflicted on our democracy.”
“Kids don’t stand a chance against the multibillion dollar Facebook machine, primed to feed them content that causes severe harm to mental and physical well being.”
With Haugen set to testify before the U.K. Parliament on Monday, activists in London staged protests against Facebook and Zuckerberg, making clear that the giant social media company should be seen as a global problem.
Flora Rebello Arduini, senior campaigner with the corporate accountability group, was part of a team that erected a large cardboard display of Zuckerberg “surfing a wave of cash” outside of Parliament with a flag that read, “I know we harm kids, but I don’t care”—a rip on a video Zuckerberg posted of himself earlier this year riding a hydrofoil while holding an American flag.
While Zuckerberg refused an invitation to tesify in the U.K. about the company’s activities, including the way it manipulates and potentially harms young users on the platform, critics like Arduini said the giant tech company must be held to account.
“Kids don’t stand a chance against the multibillion dollar Facebook machine, primed to feed them content that causes severe harm to mental and physical well being,” she said. “This industry is rotten at its core and the clearest proof of that is what it’s doing to our children. Lawmakers must urgently step in and pull the tech giants into line.”
Happening now: we are outside UK parliament with a visual protest against Facebook’s treatment of children and its business model which puts profit before public safety. (1/7) #PeopleVsBigTechpic.twitter.com/37UA18PL3r
“Right now, Mark [Zuckerberg] is unaccountable,” Haugen told the Guardian in an interview ahead of her testimony. “He has all the control. He has no oversight, and he has not demonstrated that he is willing to govern the company at the level that is necessary for public safety.”
Correction: This article has been updated to more accurately reflect the context of the comments made by Jessica González of Free Press, who responded to the revelations of a second whistleblower not those of Frances Haugen.
Originally published on Common Dreams by JON QUEALLY and republished under a Creative Commons License (CC BY-NC-ND 3.0).
Many merchants sell the exact same item, including Amazon, which picks a winner–often itself
When you shop on Amazon for a widely available product—a pair of Crocs, say, or Greenies dog treats—Amazon will pick among the merchants that offer the item and give one of them the sale when you hit “Add to Cart” or “Buy Now.”
In e-commerce, this is called winning the buy box. Amazon said its “featured merchant algorithm” picks the winner, instantly weighing available sellers’ past performance, price, delivery speed, and other factors.
Researchers at Northeastern University studying price changes on Amazon found that the merchant that won the buy box—which Amazon calls its “featured offer”—changed for seven in 10 products over a six-week period in 2016.
Five years later, we found that’s no longer the case.
When The Markup compared snapshots of 1,200 popular products 12 weeks apart, we found that the buy box was much less dynamic. The seller changed for fewer than three in 10 products in our sample.
The products we analyzed all appeared on Amazon’s first search results page of popular searches, meaning they receive prominent exposure to customers. We collected the data from an I.P. address in Washington, D.C.
Among the competing sellers for commonly available goods is Amazon itself. And when Amazon gave itself the buy box on products that other merchants also sold, it remained the buy box seller 12 weeks later for 98 percent of those products.
Overall, Amazon dominated the buy box when multiple sellers were available. We found that Amazon chose itself as the winning merchant of the “featured offer” for about 40 percent of products, while the next highest seller got the buy box in just half of one percent of popular products in our sample.
It’s hard to say why Amazon is changing the buy box winner less frequently than five years ago, said Christo Wilson, an associate computer science professor and one of the Northeastern University researchers who completed the 2016 study.
“The negative take,” he said, would be that “the market is becoming less competitive or that it’s easier for an incumbent to just sort of squat and remain stable.”
Amazon spokesperson Nell Rona declined to answer questions for this story. During congressional inquiry Amazon officials said the company doesn’t favor itself in the buy box or consider its profits in that decision.
They did acknowledge, however, that whether a product could be delivered quickly for free to Prime members is a factor in picking the seller for the buy box. Merchants typically pay extra fees for Amazon’s shipping service—Fulfillment by Amazon—to get that designation.
We found that the merchant Amazon selected for the buy box for almost every product—nine-in-10 of them—used Amazon’s shipping service. When we checked again three months later, less than 8 percent of products had changed shippers from Amazon to a third-party or vice versa.
The European Commission announced an investigation last November into whether Amazon’s criteria for the buy box results in preferential treatment for Amazon’s retail offers or sellers that use Amazon’s shipping service, which the commission said would be an abuse of Amazon’s dominant market position under E.U. antitrust rules.
In a May 2021 lawsuit, the Washington, D.C., attorney general wrote that “Amazon’s selection methods for the Buy Box winner consider factors that further reinforce Amazon’s online retail sales market dominance,” such as whether the seller uses Fulfillment by Amazon. In a court filing, Amazon responded that the lawsuit “fails to allege essential elements of an antitrust claim and, in any event, the conduct it attacks has been held by courts to be procompetitive.” The suit is ongoing.
Wilson said automated pricing algorithms may be playing a role in what The Markup found. It may also be a broader shift on the marketplace away from sellers competing to sell the same product to sellers developing their own branded products that only they are allowed to sell.
That shifts the competition away from the buy box to the search rankings, he said.
The Markup also found that Amazon gave its house brands and exclusive products a leg up in search results, above competitors with higher star ratings and more reviews, which are an indication of sales. Wilson reviewed our methodology for this investigation.
It was while testing the accuracy of findings for our main investigation that we discovered the stability of the buy box. There was a two- to four-week delay between when The Markup gathered search results and product pages. We gathered a sub-sample of listings a second time 12 weeks later to examine the effects of the delay and found they were minuscule.
“I would have thought that given that these [are] identical products and given that they are competing with similar costs, that there would be a little bit more turnover,” said Florian Ederer, an associate professor of economics at the Yale School of Management.
Shoppers can click on a link that will allow them to see more offers for a product, in addition to the one featured in the buy box. But e-commerce experts say most don’t bother: They estimate that more than 80 percent of sales on Amazon go through the buy box.
“Amazon talks about its marketplace as though it were a market,” said Stacy Mitchell, co-director of the small business advocacy group Institute for Local Self-Reliance, which has been critical of Amazon’s size and effect on retail competition in the U.S.
“This is not a market,” she added. “This is an artificial environment that Amazon controls, and it’s set up certain parameters that lead to certain outcomes.”
Eagerly awaited M1x chip expected to star and be unleashed in new Macs
For the second time in October Apple is hosting a virtual event to reveal new products and software. On October 18, 2021 at 10 the show will start, streamed as usual, from Apple Park.
Virtual events have become the norm since the pandemic restricted the possibility for live audiences. A bright side for this is that the production values for the virtual event have improved drastically in the last year and that makes for great streaming and online consumption after the fact in various forms of edited clips and screen shots.
Coming hot on the heels of the big iPhone 13 extravaganza earlier this month, this is turning out to be a big year for long awaited new products, and the M1x will potentially be the crowning achievement of the year.
Already a hit in the initial release the M series was received with a near ecstatic reaction with many in a state of awe when the upgraded capabilities were tested and measured in the wild.
As is widely known, the Intel i-7 chip was the workhorse for many years, with added cores and clock speeds helping somewhat, but with the M1 there was finally something that could usher in a new era of processors, particularly when used with optimized software from Apple and others.
With the M1x (with being the projected moniker with the actual designation to be confirmed on the 18th) there could be an even larger leap into faster, more efficient processor performance.
Gear lined up according to rumors and best intel on the street
Highly anticipated are MacBook Pros, with various larger screens and possible other hardware upgrades in addition to the new M1x, a mac mini with updated specs would be huge and many have pointed to an AirPod 3rd generation with unknown improvements.
As is often the case, if there are additional announcements they are likely to be big surprises and very interesting, the consensus is so all pervasive that is there is any deviation (like the absence of any of the above) it is going to be a shock.
The tweet from Apple Mktng SVP Greg Joswiak has a fun video that sets the tone for the virtual presentation and is likely to be followed with great content live streamed on Oct. 18th, with the option to tune in later for replays.
Even without surprises this will be a very important event with immense repercussions for all mac users. We will be covering the action live with additional details so please stay tuned.
With live view in Find My and ETA in Maps, iOS 15 is on a whole new level with keeping track of traveling significant others
Find My App (left) in iOS 15
In an update that is “just there” there has been an upgrade to the performance of the oft overlooked Find My app for iOS 15. In case you don’t use it, it’s the app that will help you find your iPhone or other iCloud connected device, as well as AirTags (or third-party geolocation products) and the devices they are attached to.
When you are following a person, generally with an iPhone or iPad (though, again the above additions and exceptions apply) you can click on that person’s name or icon (once they’ve allowed you to see their location (by turning on share my location in the FindMy app on their iPhone), in Find My and the their current location will show on the screen.
This is especially helpful, of course, if they are driving home from work, or on a road trip and you would like to follow along to see when they arrive, as examples. This level of intimate knowledge may not be necessary or appropriate for every contact in your address book (!) but between significant others (one obvious example) it can be incredibly useful.
One caveat, however, is that since this is a “stealth” update that “just works” your actual results may not be the same. Our video example was accomplished with two connected iPhone 13 Pro Max phones, both having 5G connectivity. Your results may vary.
With live view and in conjunction with the Maps app location tracking is now in a whole new universe
The update, which has been in a gradual roll-out since the public release of iOS 15 and upgraded in iOS 15.1 is a live feature where you can literally see the person (the icon or photo they have set) as they are driving, or even walking, and follow along with a moving map that updates in real time.
If used, for example while driving and using maps for the route, the map will update incrementally, showing the progress with a highlighted route all the way to the destination, while in FindMy there will be a second by millisecond live map showing the actual location as it changes. See the video above for the full effect!
The Maps app will also send notices and updates with an Estimated Time of Arrival (ETA) and will re-notify if the arrival time is significantly sooner or later (the exact amount that is deemed enough of a change to trigger a notification is unclear.
Just plain fun to watch, but also useful if the movements of a loved on are critical
There is also a secret, exclusive tip that we can divulge, which we stumbled on through trial and error. If you are watching someone driving, say on a freeway with little traffic, and they are moving smoothly along, but you want to see them at full speed, you can do the following:
Use a two-finger pinch-and-zoom gesture 3-4 times – the 3 or 4th gesture will zoom in to-the-max
Repeat #1 to maintain zoomed in status
Allow Find My live view to re-set to the standard zoom (medium)
Repeat as desired
Using this technique the person / car will be seen in an extreme close-up of the road (highway, freeway, etc.) and will appear to be traveling at the actual speed they currently are in relation to the zoom.
Think of it like a virtual drone that is following the car / person and then dives in close and has to keep pace to keep the subject in frame. Crazy.
In zoomed in mode it is also possible to do a one-finger-swipe in the direction of movement in order to keep the car / person in view (rather than letting them drive starlight off the edge of the iPhone screen).
The future is out there, and already here on your phone (with enough bandwidth and other possible requirements).
Increasing this feature to this degree of intensely detailed functionality may not be much more than a basic useful feature on overdrive, but applications for the future, for example the same feature but with satellite imagery, or maybe a simulated live view, could be a metaverse standard communication activity. We might all need to get used to having the ability to stay literally connected (in a virtual way) even as we hurtle through space. In a self-driving Apple Car, perhaps?
“How many more insurrections have to happen before we hold Facebook to account?” one group asked after whistleblower Frances Haugen said the corporation is unwilling to confront hate speech and disinformation.
Following whistleblower Frances Haugen’s Sunday night allegation that Facebook’s refusal to combat dangerous lies and hateful content on its platforms is driven by profit, social media experts denounced the corporation for embracing a business model that encourages violence and endangers democracy—and urged the federal government to take action.
Haugen, who copied a “trove of private Facebook research” before she resigned from the social media company in May, toldCBS‘s Scott Pelley during a “60 Minutes” interview that the tech giant took some steps to limit misinformation ahead of the 2020 election because it understood that then-President Donald Trump’s incessant lies about voter fraud posed a serious threat. Many of the safety measures that Facebook implemented, however, were temporary, she added.
“As soon as the election was over,” Haugen said, “they turned them back off or they changed the settings back to what they were before to prioritize growth over safety. And that really feels like a betrayal of democracy to me.”
Facebook officials claim that some of the anti-misinformation systems remained in place, but in the interregnum between Election Day and President Joe Biden’s inauguration, far-right extremists used the social networking site to organize the deadly January 6 coup attempt—something acknowledged by an internal task force’s report on Facebook’s failure to neutralize “Stop the Steal” activity on its platforms.
There is, according to Haugen, a simple explanation for why executives at the company refuse to do more to mitigate harmful social media behavior: “Facebook has realized that if they change the algorithm to be safer, people will spend less time on the site, they’ll click on less ads, they’ll make less money,” she said.
“The thing I saw at Facebook over and over again was there were conflicts of interest between what was good for the public and what was good for Facebook,” Haugen told Pelley. “And Facebook, over and over again, chose to optimize for its own interests, like making more money.”
Haugen—who first revealed her identity on Sunday after having secretly shared internal documents with federal regulators, reported on in the Wall Street Journal‘s series, “The Facebook Files”—also said the corporation is lying to the public about how effective it is at curbing hate speech and disinformation, arguing that “Facebook has demonstrated it cannot operate independently.”
In the wake of Haugen’s bombshell interview, social media experts condemned Facebook for prioritizing “profits above all else.”
“Facebook runs on a hate-and-lie-for-profit business model that amplifies all sorts of toxicity on its platforms,” Jessica J. González, co-CEO of Free Press, said Monday in a statement. “Thanks to this brave whistleblower, we now have further proof that Facebook’s executives—all the way up to CEO Mark Zuckerberg and COO Sheryl Sandberg—routinely chose profits over public safety.”
González, co-founder of Ya Basta Facebook and the Change the Terms coalition, added that Facebook executives “designed the company’s algorithms to put engagement, growth, and profits above all else, even allowing lies about the 2020 election results to spread to millions in advance of the white-nationalist assault on the U.S. Capitol.”
Longtime critics of Facebook argued that the “new revelations” about the company demand immediate federal intervention.
“How many more insurrections have to happen before we hold Facebook to account?” the Real Facebook Oversight Board, a coalition of civil rights leaders and academics, asked in a statement released after Haugen’s interview aired. “The system is blinking red, and without real, meaningful, independent, and robust oversight and investigation of Facebook, more lives will be lost.”
“The goal,” added the group, “is no longer to save Facebook—Facebook is beyond hope. The goal now is to save democracy.”
Free Press summarized the Journal‘s key findings on Facebook, which we now know stem from internal documents provided by Haugen:
Facebook exempted high-profile users from some or all of its rules; Instagram is harmful to millions of young users; Facebook’s 2018 algorithm change promotes objectionable or harmful content; Facebook’s tools were used to sow doubt about Covid-19 vaccines; and globally, Facebook is used to incite violence against ethnic minorities and facilitat[e] action against political dissent.
Shireen Mitchell, founder of Stop Online Violence Against Women, praised Haugen for exposing Facebook’s “amplification and use of hate to keep users on the platform engaged.”
Facebook has “weaponized… data in harmful ways against users,” Mitchell continued, and failed to consider the negative effects of “hate-filled rhetoric” even after the Myanmar military used Facebook to launch a genocide in 2018.
González argued that Haugen “turned evidence of this gross negligence over to the government at great personal risk, and now we need the government to respond with decisive action to hold the company responsible for protecting public safety.”
“The government must demand full transparency on how Facebook collects, processes, and shares our data, and enact civil rights and privacy policies to protect the public from Facebook’s toxic business model,” said González.
“Facebook must also act swiftly to remedy the harms it is continuing to inflict on the public at large,” she added. “It must end special protections for powerful politicians, ban white supremacists and dangerous conspiracy theorists, and institute wholesale changes to strengthen content moderation in English and other languages—and we need this all now.”
According to Carole Cadwalladr, a journalist at The Guardian and co-founder of the Real Facebook Oversight Board, “Facebook is a rogue state, lying to regulators, investors, and its own oversight board.”
“What we are seeing today is a market failure with profound, devastating global consequences,” she said. “Executives and board members must be held to account. There is evidence to suggest that their behavior was not just immoral but also criminal.”
Shoshana Zuboff, professor emeritus at Harvard Business School and author of The Age of Surveillance Capitalism, argued that “even as we feel outrage toward Mr. Zuckerberg and his corporation, the cause of this crisis is not a single company, not even one as powerful as Facebook.”
“The cause is the economic institution of surveillance capitalism,” said Zuboff. “The economic logic of these systems, the data operations that feed them, and the markets that support them are not limited to Facebook.”
“The imperatives of surveillance economics determine the engineering of these operations—their products, objectives, and financial incentives—along with those of the other tech empires, their extensive ecosystems, and thousands of companies in diverse sectors far from Silicon Valley,” she continued. “The damage already done is intolerable. The damage that most certainly lies ahead is unthinkable.”
Zuboff added that the only “durable solution to this crisis” is to “undertake the work of interrupting and outlawing the dangerous operations of surveillance capitalism and its predictable social harms that assault human autonomy, splinter society, and undermine democracy.”
Haugen is scheduled to testify on Tuesday at a Senate subcommittee hearing on “Protecting Kids Online.”
Originally published on Common Dreams by KENNY STANCIL and republished under a Creative Commons license (CC BY-NC-ND 3.0).
Frances Haugen said the company’s leaders know how to make their platforms safer, “but won’t make the necessary changes because they have put their astronomical profits before people.
Two days after a bombshell “60 Minutes” interview in which she accused Facebook of knowingly failing to stop the spread of dangerous lies andhateful content, whistleblower Frances Haugen testified Tuesday before U.S. senators, imploring Congress to hold the company and its CEO accountable for the many harms they cause.
Haugen—a former Facebook product manager—told the senators she went to work at the social media giant because she believed in its “potential to bring out the best in us.”
“But I’m here today because I believe Facebook’s products harm children, stoke division, and weaken our democracy,” she said during her opening testimony. “The company’s leadership knows how to make Facebook and Instagram safer, but won’t make the necessary changes because they have put their astronomical profits before people.”
“The documents I have provided to Congress prove that Facebook has repeatedly misled the public about what its own research reveals about the safety of children, the efficacy of its artificial intelligence systems, and its role in spreading divisive and extreme messages,” she continued. “I came forward because I believe that every human being deserves the dignity of truth.”
Facebook whistleblower Frances Haugen: "I saw Facebook repeatedly encounter conflicts between its own profits and our safety. Facebook consistently resolved its conflicts in favor of its own profits."
“I saw Facebook repeatedly encounter conflicts between its own profits and our safety,” Haugen added. “Facebook consistently resolved its conflicts in favor of its own profits.”
“In some cases, this dangerous online talk has led to actual violence that harms and even kills people,” she said.
Addressing Monday’s worldwide Facebook outage, Haugen said that “for more than five hours, Facebook wasn’t used to deepen divides, destabilize democracies, and make young girls and women feel bad about their bodies.”
“It also means that millions of small businesses weren’t able to reach potential customers, and countless photos of new babies weren’t joyously celebrated by family and friends around the world,” she added. “I believe in the potential of Facebook. We can have social media we enjoy that connects us without tearing apart our democracy, putting our children in danger, and sowing ethnic violence around the world. We can do better.”
Doing better will require Congress to act, because Facebook “won’t solve this crisis without your help,” Haugen told the senators, echoing experts and activists who continue to call for breaking up tech giants, banning the surveillance capitalist business model, and protecting rights and democracy online.
She added that “there is nobody currently holding Zuckerberg accountable but himself,” referring to Facebook co-founder and CEO Mark Zuckerberg.
Sen. Richard Blumenthal (D-Conn.)—chair of the Senate Consumer Protection, Product Safety, and Data Security Subcommittee—called on Zuckerberg to testify before the panel.
“Mark Zuckerberg ought to be looking at himself in the mirror today and yet rather than taking responsibility, and showing leadership, Mr. Zuckerberg is going sailing,” he said.
Frances Haugen strongly shakes her head in agreement as Richard Blumenthal says "Mark Zuckerberg ought to be looking at himself in the mirror" and "Zuckerberg, you need to come before this committee." pic.twitter.com/QC0B6zK9tW
“Big Tech now faces a Big Tobacco, jaw-dropping moment of truth. It is documented proof that Facebook knows its products can be addictive and toxic to children,” Blumenthal continued.
“The damage to self-interest and self-worth inflicted by Facebook today will haunt a generation,” he added. “Feelings of inadequacy and insecurity, rejection, and self-hatred will impact this generation for years to come. Our children are the ones who are victims.”
Originally published on Common Dreams by BRETT WILKINSand republished under Creative Commons (CC BY-NC-ND 3.0).
A huge but little-known industry has cropped up around monetizing people’s movements
Companies that you likely have never heard of are hawking access to the location history on your mobile phone. An estimated $12 billion market, the location data industry has many players: collectors, aggregators, marketplaces, and location intelligence firms, all of which boast about the scale and precision of the data that they’ve amassed.
Location firm Near describes itself as “The World’s Largest Dataset of People’s Behavior in the Real-World,” with data representing “1.6B people across 44 countries.” Mobilewalla boasts “40+ Countries, 1.9B+ Devices, 50B Mobile Signals Daily, 5+ Years of Data.” X-Mode’s website claims its data covers “25%+ of the Adult U.S. population monthly.”
In an effort to shed light on this little-monitored industry, The Markup has identified 47 companies that harvest, sell, or trade in mobile phone location data. While hardly comprehensive, the list begins to paint a picture of the interconnected players that do everything from providing code to app developers to monetize user data to offering analytics from “1.9 billion devices” and access to datasets on hundreds of millions of people. Six companies claimed more than a billion devices in their data, and at least four claimed their data was the “most accurate” in the industry.
The Location Data Industry: Collectors, Buyers, Sellers, and Aggregators
The Markup identified 47 players in the location data industry
“There isn’t a lot of transparency and there is a really, really complex shadowy web of interactions between these companies that’s hard to untangle,” Justin Sherman, a cyber policy fellow at the Duke Tech Policy Lab, said. “They operate on the fact that the general public and people in Washington and other regulatory centers aren’t paying attention to what they’re doing.”
A Catholic news outlet also used location data from a data vendor to out a priest who had frequented gay bars, though it’s still unknown what company sold that information.
Many firms promise that privacy is at the center of their businesses and that they’re careful to never sell information that can be traced back to a person. But researchers studying anonymized location data have shown just how misleading that claim can be.
The truth is, it’s hard to know all the ways in which your movements are being tracked and traded. Companies often reveal little about what apps serve as the sources of data they collect, what exactly that data consists of, and how far it travels. To piece together a picture of the ecosystem, The Markup reviewed the websites and marketing language of each of the 47 companies we identified as operating in the location data industry, as well as any information they revealed about how the data got to them. (See our methodology here.)
How the Data Leaves Your Phone
Most times, the location data pipeline starts off in your hands, when an app sends a notification asking for permission to access your location data.
Apps have all kinds of reasons for using your location. Map apps need to know where you are in order to give you directions to where you’re going. A weather, waves, or wind app checks your location to give you relevant meteorological information. A video streaming app checks where you are to ensure you’re in a country where it’s licensed to stream certain shows.
But unbeknownst to most users, some of those apps sell or share location data about their users with companies that analyze the data and sell their insights, like Advan Research. Other companies, like Adsquare, buy or obtain location data from apps for the purpose of aggregating it with other data sources. Companies like real estate firms, hedge funds and retail businesses might then turn and use the data for their own advertising, analytics, investment strategy, or marketing purposes.
Serge Egelman, a researcher at UC Berkeley’s International Computer Science Institute and CTO of AppCensus, who has researched sensitive data permissions on mobile apps, said it’s hard to tell which apps on your phone simply use the data for their own functional purposes and which ones release your data into the economic ether.
“When the app asks for location, in the moment, because maybe you click the button to find stuff near you and you get a permission dialog, you might reasonably infer that ‘Oh, that’s to service that request to provide that functionality,’ but there’s no guarantee of that,” Egelman said. “And there’s certainly usually never a disclosure that says that the data is going to be limited to that purpose.”
Companies that trade in this data are reluctant to share which apps they get data from.
Companies like Adsquare and Cuebiq told The Markup that they don’t publicly disclose what apps they get location data from to keep a competitive advantage but maintained that their process of obtaining location data was transparent and with clear consent from app users.
“It is all extremely transparent,” said Bill Daddi, a spokesperson for Cuebiq.
He added that consumers must know what the apps are doing with their data because so few consent to share it. “The opt-in rates clearly confirm that the users are fully aware of what is happening because the opt-in rates can be as low as less than 20%, depending on the app,” Daddi said in an email.
Yiannis Tsiounis, the CEO of the location analytics firm Advan Research, said his company buys from location data aggregators, who collect the data from thousands of apps—but would not say which ones. Tsiounis said the apps he works with do explicitly say that they share location data with third parties somewhere in the privacy policies, though he acknowledged that most people don’t read privacy policies.
“There’s only so much you can squeeze into the notification message. You get one line, right? So you can’t say all of that in the notification message,” Tsiounis said. “You only get to explain to the user, ‘I need your location data for X, Y, and Z.’ What you have to do is, there has to be a link to the privacy policy.”
Only one company spokesperson, Foursquare’s Ashley Dawkins, actually named any specific apps—Foursquare’s own products, like Swarm, CityGuide, and Rewards—as sources for its location data trove.
But Foursquare also produces a free software development kit (SDK)—a set of prebuilt tools developers can use in their own apps—that can potentially track location through any app that uses it. Foursquare’s Pilgrim SDK is used in apps like GasBuddy, a service that compares prices at nearby gas stations, Flipp, a shopping app for coupons, and Checkout 51, another location-based discount app.
GasBuddy, Flipp, and Checkout 51 didn’t respond to requests for comment.
A search on Mighty Signal, a site that analyzes and tracks SDKs in apps, found Foursquare’s Pilgrim SDK in 26 Android apps.
While not every app with Foursquare’s SDK sends location data back to the company, the privacy policies for Flipp, Checkout 51, and GasBuddy all disclose that they share location data with the company.
Foursquare’s method of obtaining location data through an embedded SDK is a common practice. Of the 47 companies that The Markup identified, 12 of them advertised SDKs to app developers that could send them location data in exchange for money or services.
Placer.ai says in its marketing that it does foot traffic analysis and that its SDK is installed in more than 500 apps and has insights on more than 20 million devices.
“We partner with mobile apps providing location services and receive anonymized aggregated data. Very critically, all data is anonymized and stripped of personal identifiers before it reaches us,” Ethan Chernofsky, Placer.ai’s vice president of marketing, said in an email.
Into the Location Data Marketplace
Once a person’s location data has been collected from an app and it has entered the location data marketplace, it can be sold over and over again, from the data providers to an aggregator that resells data from multiple sources. It could end up in the hands of a “location intelligence” firm that uses the raw data to analyze foot traffic for retail shopping areas and the demographics associated with its visitors. Or with a hedge fund that wants insights on how many people are going to a certain store.
“There are the data aggregators that collect the data from multiple applications and sell in bulk. And then there are analytics companies which buy data either from aggregators or from applications and perform the analytics,” said Tsiounis of Advan Research. “And everybody sells to everybody else.”
Some data marketplaces are part of well-known companies, like Amazon’s AWS Data Exchange, or Oracle’s Data Marketplace, which sell all types of data, not just location data. Oracle boasts its listing as the “world’s largest third-party data marketplace” for targeted advertising, while Amazon claims to “make it easy to find, subscribe to, and use third-party data in the cloud.” Both marketplaces feature listings for several of the location data companies that we examined.
Amazon spokesperson Claude Shy said that data providers have to explain how they gain consent for data and how they monitor people using the data they purchase.
“Only qualified data providers will have access to the AWS Data Exchange. Potential data providers are put through a rigorous application process,” Shy said.
Oracle declined to comment.
Other companies, like Narrative, say they are simply connecting data buyers and sellers by providing a platform. Narrative’s website, for instance, lists location data providers like SafeGraph and Complementics among its 17 providers with more than two billion mobile advertising IDs to buy from.
But Narrative CEO Nick Jordan said the company doesn’t even look at the data itself.
“There’s a number of companies that are using our platform to acquire and/or monetize geolocation data, but we actually don’t have any rights to the data,” he said. “We’re not buying it, we’re not selling it.”
To give a sense of how massive the industry is, Amass Insights has 320 location data providers listed on its directory, Jordan Hauer, the company’s CEO, said. While the company doesn’t directly collect or sell any of the data, hedge funds will pay it to guide them through the myriad of location data companies, he said.
“The most inefficient part of the whole process is actually not delivering the data,” Hauer said. “It’s actually finding what you’re looking for and making sure that it’s compliant, making sure that it has value and that it is exactly what the provider says it is.”
Oh, the Places Your Data Will Go
There are a whole slew of potential buyers for location data: investors looking for intel on market trends or what their competitors are up to, political campaigns, stores keeping tabs on customers, and law enforcement agencies, among others.
Fast food restaurants and other businesses have been known to buy location data for advertising purposes down to a person’s steps. For example, in 2018, Burger King ran a promotion in which, if a customer’s phone was within 600 feet of a McDonalds, the Burger King app would let the user buy a Whopper for one cent.
Of the location data firms The Markup examined, the offerings are diverse.
https://bookshop.org/a/565/9781479837243
Advan Research, for instance, uses historical location data to tell its customers, largely retail businesses or their private equity firm owners, where their visitors came from, and makes guesses about their income, race, and interests based on where they’ve been.
“For example, we know that the average income in this neighborhood by census data is $50,000. But then there are two devices—one went to Dollar General, McDonald’s, and Walmart, and the other went to a BMW dealer and Tiffany’s … so they probably make more money,” Advan Research’s Tsiounis said.
Others combine the location data they obtain with other pieces of data gathered from your online activities. Complementics, which boasts data on “more than a billion mobile device IDs,” offers location data in tandem with cross-device data for mobile ad targeting.
The prices can be steep.
Outlogic (formerly known as X-Mode) offers a license for a location dataset titled “Cyber Security Location data” on Datarade for $240,000 per year. The listing says “Outlogic’s accurate and granular location data is collected directly from a mobile device’s GPS.”
At the moment, there are few if any rules limiting who can buy your data.
Sherman, of the Duke Tech Policy Lab, published a report in August finding that data brokers were advertising location information on people based on their political beliefs, as well as data on U.S. government employees and military personnel.
“There is virtually nothing in U.S. law preventing an American company from selling data on two million service members, let’s say, to some Russian company that’s just a front for the Russian government,” Sherman said.
Existing privacy laws in the U.S., like California’s Consumer Privacy Act, do not limit who can purchase data, though California residents can request that their data not be “sold”—which can be a tricky definition. Instead, the law focuses on allowing people to opt out of sharing their location in the first place.
The European Union’s General Data Protection Regulation has stricter requirements for notifying users when their data is being processed or transferred.
But Ashkan Soltani, a privacy expert and former chief technologist for the Federal Trade Commission, said it’s unrealistic to expect customers to hunt down companies and insist they delete their personal data.
“We know in practice that consumers don’t take action,” he said. “It’s incredibly taxing to opt out of hundreds of data brokers you’ve never even heard of.”
Companies like Apple and Google, who control access to the app stores, are in the best position to control the location data market, AppCensus’s Egelman said.
“The real danger is the app gets booted from the Google Play store or the iOS app store,” he said.” As a result, your company loses money.”
Researchers found, however, that the companies’ SDKs were still making their way into Google’s app store.
Apple didn’t respond to a request for comment.
“The Google Play team is always working to strengthen privacy protections through both product and policy improvements. When we find apps or SDK providers that violate our policies, we take action,” Google spokesperson Scott Westover said in an email.
Digital privacy has been a key policy issue for U.S. senator Ron Wyden, a Democrat from Oregon, who told The Markup that the big app stores needed to do more.
“This is the right move by Google, but they and Apple need to do more than play whack-a-mole with apps that sell Americans’ location information. These companies need a real plan to protect users’ privacy and safety from these malicious apps,” Wyden said in an email.
Ahead of a national vote this month, Citizen Browser data shows that posts promoting the AfD party appeared more than three times as often as rivals’
Earlier this month, Germany’s far-right nationalist political party Alternative für Deutschland, or the AfD, posted on Facebook. Widespread support for Sharia law among Muslims in Afghanistan, the group claimed, illustrated the danger “wenn sich Massen von Afghanen auf den Weg nach Deutschland und Europa machen” (“when masses of Afghans make their way to Germany and Europe”).
The post was soon shared by thousands of users and commented on by thousands more. It was one of many posts by AfD-related pages over the past couple of months that railed against immigration or, another popular topic, disparaged COVID-19 restrictions as unnecessary.
Despite its modest size in Germany, the AfD has been remarkably successful on Facebook. Data obtained through The Markup’s Citizen Browser project, in partnership with Germany’s Süddeutsche Zeitung, shows how the AfD has gained tremendous traction on Facebook in the run-up to a historically contentious national election to replace Angela Merkel, the long-serving chancellor, later this month.
The Citizen Browser project, which collects data from a diverse panel of 473 German Facebook users, shows the party and its supporters have peppered Facebook with pages promoting its ideology, with posts on those pages appearing in our panelists’ news feeds at least three times as often as those from any rival party.
Fewer unique panelists had posts from AfD-related pages appear in their news feeds than posts from the sister parties of the Christian Democratic Union of Germany (CDU) and the Christian Social Union in Bavaria (CDU/CSU), which led in this count, and from Bündnis 90/Die Grünen (Alliance 90/The Greens). But the data shows AfD deeply engaged with its core audience: The users who did see content from the AfD tended to see it repeatedly, and the AfD was especially good at reaching its own supporters.
Citizen Browser captures up to 50 posts from a panelist’s Facebook news feed one to three times a day. The Markup catalogued every time a post from a page named for a German political party appeared in our panelists’ feeds over the past two months, from July 20 to Sept. 16, 2021. We included any pages that mentioned “AfD” or one of its political rivals (“SPD,” “CDU,” or “FDP,” for example) in its name. We did not determine whether the page was officially sanctioned by the party itself. We removed any pages meant to disparage a party.
Posts from more than 200 different pages promoting the AfD party—the most pages of any party we looked at—appeared in our panelists’ feeds. While the quantity of pages promoting the center-left Social Democratic Party, the SPD, followed closely behind with 175 pages, posts from AfD pages appeared four times as often in our panelists’ news feeds. Our panelists were shown posts from the AfD more than 3,200 times, while they were shown SPD posts only about 760 times.
The other major political party in Germany, the center-right Christian democratic political alliance, or the CDU/CSU, fared slightly better. Posts by pages related to those parties appeared in panelists’ news feeds around 850 times. But the AfD’s posts still appeared more than three times as often.
The AfD’s dominance of our panelists’ news feeds is especially stark considering the makeup of our Citizen Browser panel in Germany. Our panel consists of more people who identified themselves as SPD and CDU/CSU supporters—62 and 82, respectively—than the 44 who identified themselves as AfD supporters.
Those who did report aligning with the far-right party had an average of 55 posts from AfD-related pages appear in their news feeds in the eight weeks of data we examined. By comparison, supporters of the CDU/CSU had an average of just six CDU- or CSU-affiliated posts appear in their feeds.
“Given its very limited number of participants, data from The Markup’s ‘Citizen Browser’ is simply not an accurate reflection of the content people see on Facebook,” Facebook spokesperson Basak Tezcan said in an emailed statement. “We actively reduce the distribution of content that is sensational, misleading, or are found to be false by our independent fact-checking partners. Our approach goes beyond addressing the issue post-by-post, so when Pages or Groups repeatedly share this kind of content, we reduce the distribution of all the posts from those Pages and Groups.”
The AfD did not respond to a request for comment.
Our analysis has limitations. Citizen Browser tracks a small percentage of Facebook users in Germany compared to the tens of millions of Germans on the platform and is unlikely to perfectly mirror what Facebook shows all of its users in Germany. On Sept. 1, Facebook introduced a new interface that affected captures for 3 percent of the panel across all parties. Some captures for this small subgroup of panelists could not be included in this study.
But the panelists represent a diverse set of party affiliations across the political spectrum in the country, from AfD supporters to centrists to far more liberal users.
And AfD’s savvy on Facebook has been documented in past elections.
The AfD’s Rise on Social Media
The AfD launched in 2013, initially as a conservative party harnessing skepticism of the European Union. Though it failed to reach the vote threshold for representation in the German Bundestag in the federal election that year, the group’s facility with social media quickly became evident.
“Directly in their beginning, in 2013, they began to install a very strong network of interconnected Facebook accounts for nearly all local branches of the party,” said Isabelle Borucki, an interim professor at the University of Siegen who studies German political parties online. The AfD operates on many platforms, but Borucki said it was clear the party “understood especially how this network works.”
It isn’t just Facebook where the AfD has performed well, either. This year, a report from Süddeutsche Zeitung and AlgorithmWatch that relied on data from hundreds of users showed how Facebook-owned Instagram seemed to favor right-wing content, with posts from the AfD tending to appear higher up in users’ feeds.
While it’s difficult to say how social media popularity translates to votes, many observers have attributed the AfD’s growth, at least partially, to its social media strategy.
“They managed to use social media to explode and find people and citizens that weren’t interested in politics before,” said Juan Carlos Medina Serrano, a Ph.D. student at the Technical University of Munich who has studied the AfD’s use of social media and is now heading data operations for Germany’s Christian Social Union party.
In past elections, researchers and journalists have tried to measure how well the AfD has reached users on Facebook compared to other political parties. Like The Markup, they also found that the AfD has been able to use Facebook to find a large online audience.
After the 2017 national election, a Washington Post analysis noted that AfD posts had been shared more than 800,000 times that year, far outpacing all other major parties put together.
In 2019, one report found that AfD posts on Facebook accounted for about 85 percent of shared content from German political parties, according to Der Spiegel. A researcher told the outlet at the time that the AfD had become “the country’s first Facebook party.”
Facebook has highlighted its efforts to combat misinformation in past German elections. In 2017, after the last German federal election, the company said it had removed tens of thousands of suspicious accounts to clamp down on the spread of false information.
Facebook also announced earlier this month that it had removed a network of pages associated with Germany’s anti-lockdown Querdenken movement that promoted violent content and health misinformation. The movement is not directly aligned with a political party, although it shares its COVID-skeptical perspective with the AfD.
This month’s vote may present new challenges for the social network. In June, Politico reported that there had been a spike in election-related misinformation as far-right social media users appeared to be laying the groundwork to make claims of election fraud after the vote.
What’s Driving the AfD’s Success on Facebook?
Experts point to several factors that have contributed to the AfD’s Facebook presence.
As the Citizen Browser data shows, the AfD and its supporters tend to run more active pages in general than their rivals, setting up relatively small, localized pages that garner support across the country.
The AfD, researchers say, also relies more on sensational, aggravating content, which is a perspective Facebook rewards with greater reach. “They trigger anger, fear—I would say anarchic or basic emotions,” Borucki said. “Those trigger people and affect people more than bare facts.” One recent AfD post found in our dataset bemoaning “climate hysteria,” for example, led to more than 5,000 “angry” reactions on Facebook.
This strategy seems to be catching on with other political groups. The Wall Street Journal reported last week that some European parties had shifted policy positions to align with what performs well on Facebook, including more negative content.
The CDU didn’t respond to The Markup’s requests for comment, and the SPD declined to comment.
Like many conservative politicians in the United States, the AfD has been eager to court voters skeptical of COVID-19 restrictions and vaccines, leaning into a populist stance against preventative COVID-19 measures.
Facebook says it attempts to automatically tag any content related to COVID-19 with a flag sending users to reliable information. The Citizen Browser data shows that, of the posts shown to our panelists, posts from the AfD were by far the most likely to be tagged by Facebook as being related to COVID-19. Our panelists were shown AfD posts tagged by Facebook for being COVID-related more than 250 times. In contrast, our panelists were shown posts from the SPD with tags related to COVID-19 fewer than 15 times, and this was the second most tagged in our dataset.
Many of the AfD posts inveigh against lockdown measures and suggest that the vaccines may not be as effective as health officials claim. A post about infections spread in a club that required proof of vaccination, for example, called vaccine-related restrictions quatsch, or nonsense.
The group’s posts remain popular, but it’s also not clear whether those posts are leading to new votes. The party is projected to end up in fourth or fifth place in the upcoming election.
Since the 2017 election, Medina Serrano said, the AfD’s explosive growth on Facebook seems to have leveled off. Now, he said, the party has gone from a strategy of looking to pull in new voters to one of cementing its base in German politics through Facebook.
“It’s more about maintaining the base than growing—it’s already capped, in my opinion,” Medina Serrano said. “But we’ll see the results on election night.”
Above: Photo Collage / Lynxotic / J. Flavia / Unsplash
Ear related! 2nd best and more are also interesting
With so many new features on the iPhone 13 Pro models, and with so many of them made possible by iOS 15, the A15 bionic chip, the 16-core Neural Engine, which performs up to 15.8 trillion operations per second, and power features like Cinematic Mode and Smart HDR 4, machine learning and other hard to explain facets of the overall experiential upgrade, sound playback (and recording) are often barely mentioned, it seems.
Ever since there was the biggest Apple success story near the turn of the century there has been a special relationship between the fruit company and music / sound. I’m talking, of course, about the iPod.
Long before the iPhone was even a rumor, the iPod was a huge success, taking over the mp3 player market and, with the iTunes store for music downloads, launching the software and services division, for all practical purposes.
It’s hard to imagine now, but there was doubt that Apple could make it in the competitive cell phone market, with behemoths like Nokia and Blackberry so well established. It was the iPod’s success that made it seem plausible.
There was one thing that the iPod never had, however; speakers. And even the recent iPhones, with speakers for voice and music, if you didn’t use your AirPods for that, had speaker and sound quality that was not on the quality level of the larger iPads.
With a much larger area to hide speakers, the iPad was always an obvious choice for watching movies and listening “out loud” via the built in speaker system. With an iPad pro that could be pretty spectacular with a relatively full frequency spectrum and, more recently via software upgrades, spatial audio.
With iPhone 13 Pro models the audio barrier has finally been shattered
In a tiny, nearly forgotten passage at the very end of a list of new specs and enhancements in the iPhone 13 line, Apple adds one more thing; a stereo speaker at the top where the notch is located and a second stereo speaker at the bottom next to the Lightning port.
What it doesn’t mention is the improvement in the sound quality. Like so many features in the newer generation of devices and software, this unassuming, seemingly simple statement is just the tip of the iceberg and does not divulge what’s really going on.
Once more a combination of all the recent software and hardware upgrades combine to produce an experience that goes beyond what you could expect with these tiny, nearly invisible, speakers.
First, the two stereo speaker sets are, sound wise, equal in quality. So when you are watching a movie in landscape mode there is a distinct stereo effect. This is enhanced by spatial audio and dolby atmos depending on your set up.
The actual experience is noticeably “iPad like” and in some ways even goes beyond. Having the phone relatively near you, due to its size, and listening to a high quality movie score, there’s a feeling that your phone has morphed into a personal theater – as long as you can let the sound out into your local environment.
Try “SharePlay”, once it’s live in iOS 15.1, or just manually sync with your partner, assuming you each have a new iPhone 13 (!) and you will get a glorious room filling surround experience from the 4x stereo output (8 speakers?!) into the room.
And the mysterious mics also hidden in multiple places, are also a big upgrade – the seem to switch roles for video, calls etc and maximize the audio quality in live recording situations.
Apple’s software and service bundles and ambitions are driving hardware and iOS upgrades
As jubilant as this may sound, there is also an ulterior motive lurking. Some of the audio features work best (or at all) with an Apple Music subscription. And having more subscriptions, Apple TV, Apple News, Apple Music, iCloud Extra Storage, along connected devices, with so many available, it becomes an ecosystem of plenty for Apple, already the largest company by market cap.
On the optimistic side there’s always Apple One Premiere, the top of the line for bundled services (see below) and looking more and more like a steal at $29.95 per month.
Perhaps, one day not to far away, there will be a Apple One Premiere plan that also includes all Apple devices and you just trade them in every two years (every year?) or maybe you never own them at all?
The way the upgrades in hardware, software and the rest are becoming more interdependent and how crazy it already is to upgrade various devices (assuming you have more than one or two) yearly or bi-annually it’s an interesting idea to try and imagine.
And with an Apple Car perhaps on the way (self driving and outfitted with all the rest of the tech and service bundles) this could be a whole-house, whole-office (will there still be offices?) all transport bundle too. Apple haters will be in trouble, and have to move to Google Island, but otherwise, hey, why not?
Apple One Premiere example package:
Speakers after tear down by iFixit:
credit: iFixit
Audio Playback
Audio formats supported: AAC‑LC, HE‑AAC, HE‑AAC v2, Protected AAC, MP3, Linear PCM, Apple Lossless, FLAC, Dolby Digital (AC‑3), Dolby Digital Plus (E‑AC‑3), Dolby Atmos, and Audible (formats 2, 3, 4, Audible Enhanced Audio, AAX, and AAX+)
Spatial audio playback
User‑configurable maximum volume limit
Video Playback
Video formats supported: HEVC, H.264, MPEG‑4 Part 2, and Motion JPEG
HDR with Dolby Vision, HDR10, and HLG
Up to 4K HDR AirPlay for mirroring, photos, and video out to Apple TV (2nd generation or later) or AirPlay 2–enabled smart TV
Video mirroring and video out support: Up to 1080p through Lightning Digital AV Adapter and Lightning to VGA Adapter (adapters sold separately)9
Upgrades for hard and software, though groundbreaking and exciting, do have limitations and problems
The new upgrades for iOS 15, iPad OS 15, mac OS 12 Monterey and the rest are in many ways amazing, feature filled wonders, as we’ve discussed at every opportunity. The multi-year transition to a more unified system across all apple devices is underway and we are big supporters of the benefits.
However, nothing is perfect, and particularly in the early days it is to be expected that glitches and strange twists and turns in the journey can disappoint and confuse along the way.
Below we’ve outlined a few.
Various less than perfect ideas and execution in the OS software
Some issues are not really issues at all but things that people just don’t like. One example is the move of the address bar on safari in iOS 15 to the bottom. Many people had trouble getting used to this so a button was added to move it back to the top.
Other glitches include a false warning that you are out of storage space. Others have reported a reduction in perceived (if not real) battery life. Although these are minor annoyances and will be fixed with future updates, such as iOS 15.1 due any minute now, they show that this bug hunting is, unfortunately part of the process of any upgrade, much less a huge and important one like iOS 15.
There are also specific limitations though that should be mentioned about the iPhone 13 Pro camera system.
This issues are less bugs or errors and just limitations that may, or may not, be improved at a later date.
The new high end Pro camera system for the iPhone 13 Pro series is a major upgrade that has so many features and new capabilities that it is hard to even list them all, let alone illuminate the multitude of options and enhancements that they create.
On the obvious down side, however, a few things have jumped out at users now that these phones are in the wild.
Cinematic mode only works (currently) in 1080p. This is a serious limitation, since the whole idea of “Pro” is 4k and above. Many even go so far as to say that 1080p aka HD is no longer the standard for video and even obsolete. While there are rumors that this could get a software upgrade, perhaps even before the next iPhone model next fall, but it is not at all clear if, or when, that might happen.
This limitation is a fairly serious one, since an entire project would have to be shot at 1080p HD rather than 4k to make any use at all of the beautiful and fascinating rack-focus effects available in cinematic mode.
Less and issue but often mentioned is the inability to shoot 4k slow motion footage.
The lack of slo-mo at any resolution above 1080p is also something that has surprised aficionados. There is an option for 1080p at 240 fps, but unless you are shooting ultra high speed action that is not a hugely useful setting.
It seems odd, since a large part of the limitation is likely the large amount of data required to make this happen at 4k but there is a silver-lining here that few have mentioned in recent articles decrying the lack of 4k slow-mo options.
Since the system is already capable of shooting 4k at 60fps, and a final project setting for editing could be 4k at 30 or even 24fps, the 4k 60fps could be seen as a double speed slo-mo setting for a 4k video projects shot at 30fps for standard and 60fps for footage to be slowed to 30fps for the 1/2 speed slo-mo effect.
In the feature film 35mm celluloid days this was a very common and useful way to get slow-mo without eating up tons of expensive film stock.
Also, shooting at 4k 60fps for a 4k 24fps project would yield a 1.5 ratio of frame rate, giving an even more extreme slow-mo effect. For most slow motion effects 1 to 1.5x speed in-camera for later playback at the project rate is more than adequate.
The 120fps rate, since the top frame rate at 4k is 60fps, is, indeed, double which, as stated above, standard.
Therefore, for all practical purposes, there is already a way to produce beautiful 4k slow motion effects in a 30fps or 24fps project and have those be in camera pristine slo-mo and not the less desirable edit-only EFX.
Summing up, even with glitches and minor disappointments, it’s a beautiful world and now we just have to shoot it
If no more serious glitches or known issues pop up during the transition from iOS 14 to iOS 15, and iPhone 12 Pro to iPhone 13 Pro, we can be satisfied that this is a monumental job well done by the gang at Apple.
Though there are a lot of shortcomings that we may perceive in the new world topping combo-pack; iPhone 13 Pro Max running iOS 15.1, these are when compared to far more costly and cumbersome alternatives, or simply, when compared to our wildest dreams. Those will have to wait a few years, in all likelihood.
Human greed is a powerful thing. When given a photographic system that even attempts to approximate a profession system based on prime and zoom lenses and accessories, there’s a tendency to want it all, right now!
Of course, instead, what we get is an amazing extension of the iPhone photo tradition – taken up a bunch of notches at once. The computational enhancements are incredible and will only get better – in many cases without a new phone as they are based on AI and machine learning, which as the name implies, are continually improving while you sleep.
It is also the reason why real lenses and traditional DLSR cameras still have an important use and value.
The new system unveiled with the iPhone 13 pro is revolutionary precisely because of the potential for people to create new visual expressions and ways of communicating.
These photographic traditions and the efforts that were made in the design to emulate them are important and valuable. However, the future will benefit from the spontaneous and new ways that people will decide to use this evolving system and the current extensions of our eyes, ears and minds….



















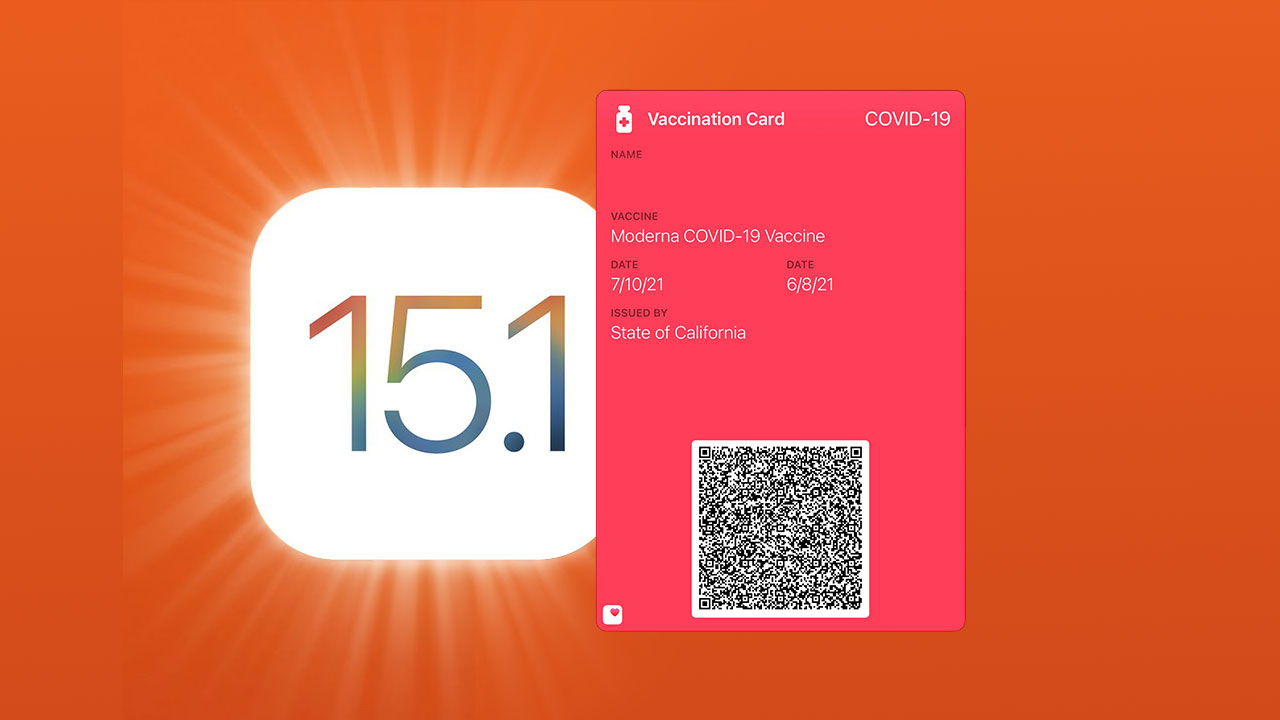

















![READY PLAYER ONE - Official Trailer 1 [HD]](https://i.ytimg.com/vi/cSp1dM2Vj48/hqdefault.jpg)













































:format(webp):no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/22877338/earpiece_ifixit.png)




