Ok. So it will be what you make of it. There’s not going to be a seamless leap from a heavy web2 monstrosity like what Twitter has become to a clean alternative overnight.
It makes sense, though. A platform that’s built to monetize your life, and does so on a massive scale, can’t be replaced easily by an entirely different beast.
Mastodon is not based on blockchain, for a social platform that is blockchain based, check out Lens Protocol, but does have an open source, ad-free structure that is controlled by users. It is also a microblogging network based on a UX that somewhat resembles Twitter.
As a “Federated” network system, Mastodon has various servers, each of which run by users, and differentiated, for the most part, by affinity.
Basically, rather than having a centralized corporate entity controlling and monetizing your account and data, you trust a peer who has set up a server. You can choose and join a group (server) based on the theme, rules and configuration of that server / moderator. In some cases you will need to be invited or prove worthiness, but such stipulations are set by the moderator and group.
Are we, ex-Twits, sophisticated enough to take on digital self-determination?
The challenge lies in the trade off that is built into the systems, one vs. the other. On a highly commercialized, slick, UX optimized platform like twitter there are lots of addictive, albeit shallow, reasons to participate. And the downsides can be seen everywhere – massive bot harassment, constant DMs from unwanted scammers, hate and ugliness, you get the picture.
A user controlled, open source platform, on the other hand, requires more real engagement from everyone for it to work. This is a double-edged sword – all that extra effort can seem overwhelming, but the benefits, particularly longer term can be magical.
Imagine a place where you are free to communicate with others that share your interests, and those that may not, but without an algorithm to force you to see whatever it wants you to see, or to shadow-block you from being seen, only because you didn’t pay or play its preferred game.
Losing the algorithm that serves the centralized commercial platform’s agenda is, ultimately, the only way forward, but not an easy place to get to.
In the end it is a question of realizing the potential of the internet (web2, 3 or 4) for deeper and more effective communication, not just to create a hellscape of fluff and vitriol that benefits a Zuckerberg and now, potentially, Elon Musk.
By now the shortcomings of Facebook (Meta), Twitter and the various Google services are glaringly obvious and, for the most part, agreed on nearly as much as global warming. However, just like the solutions to that other soon-to-be hellscape, the possibility of millions or even billions of people (in the case of Facebook) spontaneously migrating to a new platform or platforms is slim.
Ultimately, it will take a change in the people that comprise the network itself, not a top down makeover or feature-set rollout.
That is the most interesting point that can be gleaned from the current Mastodon moment; those that have pre-migrated before the current Twitter melt-down era seem to be acutely aware of the challenges, but also of the potential benefits, of growing into the new experiences that are only available there.
This underscores the potential irony of the current Twitter meltdown, intentional or not. Is Elon Musk doing the world a favor by pushing many of the best and brightest communicators out of the nest at the precise moment that it might be possible for another platform to gain a foothold?
Or will this be more akin to the moment that Clubhouse had which was seemingly diluted and washed away by copycat offerings (like the audio services Twitter added) and demoted to near irrelevance?
As has been the case in the past, even with the initial adoption of Facebook and Twitter by the masses, it is user sophistication and need that drives huge new platforms and activities.
Whenever a new platform for online communication is able to meet the moment and the new needs of a critical mass of users, that will be the place and time for the past to fade and something, hopefully better, to emerge.
And, perhaps, learning how to better interact with one-another online, even at the cost of taking more responsibility for learning and co-managing the platform itself, will begin with Mastodon and the Twitter devolution phase.
The following excerpt from TheMarkup.Org, from an interview by Julia Angwin of Adam Davidson gives a bit of a view into what some might find worthwhile at Mastodon:
Angwin: What would you say your biggest takeaway from this experience has been so far?
Davidson: I would say the screaming headline for me is, “Wow, this was awesome. This was amazing.” The Mastodon community was amazing. The journalism community was amazing. It’s really one of the best professional experiences of my life. I just love it.
What I’m finding most satisfying about Mastodon, and I’m seeing a lot of other journalists feel this, is that it actually forces you to ask and confront some of these questions and to make active choices. Even if Mastodon were to remain Twitter’s very tiny stepbrother, I would still like to be part of a Mastodon journalist community because I think we got lazy as a field, and we let Mark Zuckerberg, Jack Dorsey, and, god help us, Elon Musk and their staff decide all these major journalistic questions. I don’t know for how many people that’s a good siren call to join Mastodon, but for me that’s been pretty exciting.
Straight from a follower named “Spam Bot” the real reason…
Yesterday we published a story featuring a theory floated by a lady who, apparently, worked for Tesla for a decade, who believes that Elon is a “humanist” and wants to save the planet and needs Twitter to help him better communicate his ideas and solutions. No, not reinstating Trump, but she claimed it was all about global warming.
Not long after that article hit the airwaves, “Spam Bot”, reacted and posted a message (see photo below) where he (or she? or they?) outlined what’s really goin’ on:
Here’s the posted text in its entirety:
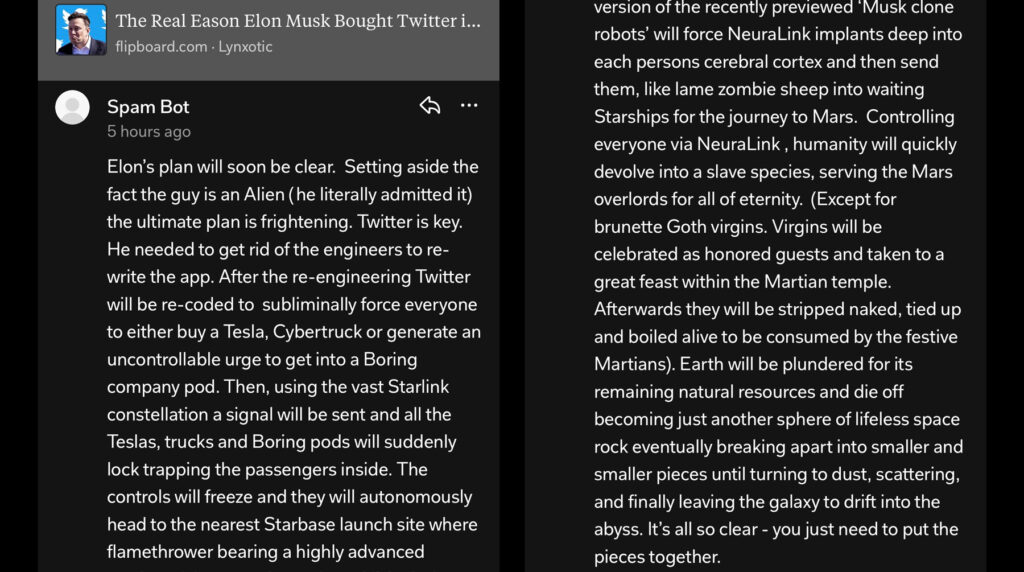
“Elon’s plan will soon be clear. Setting aside the fact the guy is an Alien (he literally admitted it) the ultimate plan is frightening. Twitter is key.
He needed to get rid of the engineers to rewrite the app.
After the re-engineering Twitter will be re-coded to subliminally force everyone to either buy a Tesla, Cybertruck or generate an uncontrollable urge to get into a Boring company pod.
Then, using the vast Starlink constellation a signal will be sent and all the Teslas, trucks and Boring pods will suddenly lock trapping the passengers inside.
The controls will freeze and they will autonomously head to the nearest Starbase launch site where flamethrower bearing a highly advanced version of the recently previewed ‘Musk clone robots will force NeuraLink implants deep into each persons cerebral cortex and then send them, like lame zombie sheep into waiting Starships for the journey to Mars.
Controlling everyone via NeuraLink, humanity will quickly devolve into a slave species, serving the Mars overlords for all of eternity. (Except for brunette Goth virgins. Virgins will be celebrated as honored guests and taken to a great feast within the Martian temple.
Afterwards they will be stripped naked, tied up and boiled alive to be consumed by the festive Martians).
Earth will be plundered for its remaining natural resources and die off becoming just another sphere of lifeless space rock eventually breaking apart into smaller and smaller pieces until turning to dust, scattering, and finally leaving the galaxy to drift into the abyss. It’s all so clear – you just need to put the pieces together.”
If anyone is offended (or frightened ) by that, apologies on behalf of Lynxotic. As a writer it is important to always have something to say. This, text, this outpouring of strung together amalgamation of brand names and alien motivations has rendered this scribe… almost speechless…
To unpack this, in spite of being dumbfounded, the first thing that comes to mind is that “Spam Bot” gives Elon too much credit. Sure, he has admitted to being an alien, yes he is the wealthiest person on the planet, sure, his companies do all seem to fit together in a neat little puzzle that could enable exactly such a scenario…. But, no, it is not likely (hahaha) that this scenario is true, at least not all of it.
Actually, the idea that it was Elon’s intention all along to fire nearly all of Twitter and the mass exodus was what he wanted all along, does kind of make sense. If he really does want to rebuild it from the ground up, what better way to get rid of nearly all the employees than to find a clever (?) way to get everyone to quit (without looking really bad for firing everyone just before the holidays) .
And it will be quite entertaining to see how this plays out. For example, as we note in a new article coming today, Mastodon is growing fast and there’s an interesting possibility that a migration en mass over there could be a major upgrade.
Bitcoin’s history and origination is an important factor for more than just true believers and maximalists. Created in the aftermath of the 2008 financial crisis, and with evidence that it was intended, by its founder, known only as Satoshi Nakamoto, as remedy for the failed system that had nearly collapsed the world economic system at that time.
In a recent CoinDesk post, Nathan Thompson wrote: Bitcoin’s genesis block is historic, not just because it contained the first 50 bitcoins, but because it had a message coded in the hash code: “The Times 03/Jan/2009 Chancellor on brink of second bailout for banks.”
The bank bailouts and various financial system failures were integral, then, in the creation and purpose of bitcoin, and one could even say, coins and systems that followed, starting with Ethereum in 2015.
After a few weeks of tweets revolving around the Twitter buyout brouhaha, Elon Musk, in a reply, added, in a more introspective tone than has been seen of late, some of his thoughts on the subject;
The axiomatic error was that housing prices only go up. I don’t support predatory lending, but many of those lenders were severely wounded or didn’t survive.
They dug their own graves – a lesson we should all take to heart, including me.
Interesting timing and a nice shift from the obsession with prices
The recent “crash” and panicked voices over the drop of the bitcoin price below $30k is the unspoken background addressed in this exchange, it appears.
Decrying the erroneous belief that “prices only go up” held by the public at large during the doomed run up to the 2008-2009 crisis could be seen as a hint that, perhaps, prices of assets like Bitcoin, and Tesla shares, for that matter, can not “only go up” and anyone who seeks such a preposterous nirvana is digging their own graves, having failed to learn from all the times in history that fools took the path of peak greed and self-delusion.
Worse, and worth being singled out specifically, are those that profited from the delusion of others in “predatory lending” practices, which Elon Musk “doesn’t support”.
Ultimately for this tweet thread, it was Elon Musk’s Twitter buddy @BillyM2k that nailed it with a series of tweets explicitly spelling out the divergence between the founders and believers in the original, positive, intent of bitcoin and the massive bubble of speculators and scammers that has, in his view unfortunately, grown up around it.
Pointing out that DogeCoin, as an example, was created to highlight the stupidity of speculation and excess greed that came with the avalanche of meme-coins and “shitcoins” etc, that flooded the market and, to a great degree, obscured the original, positive force that bitcoin and decentralized finance was invented to be.
Maybe, some of the various challenges and stumbles that Elon Musk is experiencing lately, seemingly for the first time, after a string of incredible triumphs, culminating with the Person of the Year designation and the buyout launch that is now in limbo, will inspire him to be more reflective and use his powerful position as a “Twitter-sage” to draw more attention to the need for a voice of “reason”, rather than as a cheerleader for the bonfires of vanity and speculation.
Perhaps in a moment of incoherence, this three-tweet set was launched. It is just plain goofy (unless he is buttering up “the right” for after mid-terms…?)
In what looks like some kind of twisted attempt at being diplomatic, Elon Musk’s latest tweet manages to clarify his stance regarding “free-speech“ about as much as a mud bath clarifies a cupcake.
Leading off with a bizarre attack on what he Calls “the far left “, he explains that it is his contention that they “hate everyone including themselves”.
Standing alone this is already a bizarre statement, which seems like a far right talking point, typical of the Joe Rogan school of anti-cancel culture and anti-so-called “woke-mob”.
He follows this up with a disclaimer of sorts, as bland as it can be stating that he is “no fan” of the far right, either.
One would have to be forgiven if they thought that this implied, in its very wording, an actual bias toward the far right which is what many already believe.
Ending his three-tweet soufflé on the flat “Let’s have less hate and more love” the responses, not surprisingly, were a very loving mix of WTF and ????
To be fair, there were also lots like this:
If you ever run for President of United States 🇺🇸 you definitely have my vote 🗳 You are awesome my friend 🙏
But, the way his tweets were so oddly posted, there was definitely a sense among “lefties” that he was biased. And it didn’t take a genius, but merely @cjwalker21, to retort:
It actually seems odd, that Elon Musk would wade (or dive head first) into a “left vs. right” argument that has no hope of any kind of resolution. And pretending that the disagreements are equal on some level and love can just be ratcheted up as if it was cheap rocket fuel, seems odd…
In the US, far left is free healthcare and education, far right is no abortions allowed.
Honestly, if you just look at the numbers, maybe you don’t see taxes as the answer, but considering the company Elon is in (Zuckerberg and Bezos?) there’s clearly something wrong with this picture?
Even for Twitter the reaction is bizarre to the extreme
Wow. The big news came, simple and straightforward, on Monday afternoon. Eastern time. From the official press release: “Twitter, Inc. (NYSE: TWTR) today announced that it has entered into a definitive agreement to be acquired by an entity wholly owned by Elon Musk, for $54.20 per share in cash in a transaction”
What came next was a tsunami of extreme emotions – mostly negative by casual observation. The happiest seemed to be MAGA dreamers that somehow think that Elon Musk will be all about enabling Trump and his minions to get back into social media shenanigans, a.k.a. “free speech’. Which is, to put it mildly, doubtful.
To get the color of this intense reaction here are just a few example headlines:
Oddly, the most ferocious detractors of this deal are the “left” and those that are also believing the nonsense that somehow this is a big win for the right and for Trump (huh?) and therefore – the friend of my enemy is my enemy, or some such thing.
Naturally, Trump says he would not tweet again even if invited since he has his own useless and failed app. This is the basic problem of 90% of the reactions – the more extreme they are the more ridiculous the assumptions as to what Elon Musk will actually do.
Bots, often controlled by foreign actors, were the issue in 2020, not the tweets by actual people
If you were on twitter in 2020 during the run-up to the election, or in 2016 for that matter, the biggest issue was not the real tweets from Trump and others of his ilk, no matter how stupid and deranged those tweets were.
It was, instead, the thousands of fake accounts amplifying the “message” and creating a wall of lies and disinformation. Those bots would attack any anti-Trump or Pro-Biden (or Pro-Hillary) tweets and applaud all pro-Trump messages with likes, re-tweets etc. And they still exist to today.
They were ridiculously obvious as fake, for anyone who bothered to check, but the massive number and the fact they they were allowed to run-rampant made this stupid, primitive method of perverting actual free speech and behavior bizarrely successful.
This is just one small point. The idea that Elon Musk bought Twitter so that he can re-instate Trump and his bot-army goes against literally everything that is known about him as well as what he has actually said.
Of course anyone can say that Musk is not sincere, etc. But stating unequivocally that he will defeat the bots is a step in the right direction. Bots and fake accounts are epidemic in all social media and are likely tolerated for nefarious reasons – the least negative of which would be that it’s too expensive to care.
The fact that he would make mention of the “shadow ban council” also shows an awareness of the problems associated with algorithms that have agendas that punish and shadow ban at the whim of those in charge as being important- < it is > – that’s a huge plus, at least in terms of transparency or dialog about actual problems that exist.
And let’s not forget that Elon Musk is not beholden to a specific political party (everyone accuses him of being on the other side or of being a libertarian, and that maybe a good fit for some of his expressed views, but he has not specifically aligned himself with a particular party).
What this all boils down to – as alluded to in the title, is that there’s a strong sense that nearly all these opinions and much of the outrage is dead wrong about what will actually happen.
Can Elon Musk ‘Fix’ Twitter?
It would be equally insane, however, to assume that anyone, even the world’s richest person, can just buy Twitter, or any other huge tech platform (Web2 platform) and then fix all the problems.
The idea and service is all that matters to me, and I will do whatever it takes to protect both. Twitter as a company has always been my sole issue and my biggest regret. It has been owned by Wall Street and the ad model. Taking it back from Wall Street is the correct first step.
Can anyone even agree on what Twitter is or what it should be? And so many of the problems that twitter has are baked-in to the whole huge-Web2-platform-defacto-monopoly thing that makes life online so frustrating and, at times, hopeless.
But what a private company, run by a “brash” gazillionaire is, at least, is something different. Well, sort of. That’s where it comes down to a probably crazy experiment in just how much worse can it get… Zuckerberg, Bezos, the Google Twins? Tough acts to follow?
Some have pointed out that Elon Musk will have even more power and control over Twitter than, for example, Zuckerberg has over FaceBook-er-Meta. And that is, for some, a scary and infuriating concept. On the other hand, what if more control, in the hands of someone who at least appears to have a sincere desire to see Twitter succeed as a “Town Square” and communication tool for humanity is actually what it takes to get things on the road to betterville…?
It’s hard to give a guy with $350 billion the benefit of the doubt, I get it
In other words, instead of seeing Twitter as a battleground between left and right, where one or the other should “win”, there is at least the possibility that Elon Musk sees it as much more than that.
That he sees it a bit closer to what it was created to be – a tool for people to communicate is a novel way.
Call it micro-blogging or shit-posting or memeifycation of life or what you will, the idea is, that if it were possible to create a tool that did indeed allow and even encourage actual online free speech is one that could at least be an experiment worth trying.
Is ‘this guy’ the right person to do it? Maybe not. Is a public company, with the explicit primary goal of enriching shareholders a better way? Not so far in any known example.
In fact this seems to be the ‘secret’ that is hiding in plain sight, that an altruistic goal by a super-rich private individual who decides to take over a social media company, to try to do something never done before – might actually be exactly what it takes to begin a new way for people to communicate online.
And, regardless of how skeptical we may be of that idea, the fact is that extreme change is urgently needed – leads to the reality that anything new and different should at least be tolerated and tried before it is condemned and attacked.
“Despite half of U.S. and U.K. adults getting their news from social media, social media companies have not taken the steps necessary to fight industry-backed deception,” reads the report.
Weeks after the Intergovernmental Panel on Climate Change identified disinformation as a key driver of the planetary crisis, three advocacy groups published a report Wednesday ranking social media companies on their efforts to ensure users can get accurate data about the climate on their platforms—and found that major companies like Twitter and Facebook are failing to combat misinformation.
The report, titled In the Dark: How Social Media Companies’ Climate Disinformation Problem is Hidden from the Public and released by Friends of the Earth (FOE), Greenpeace, and online activist network Avaaz, detailed whether the companies have met 27 different benchmarks to stop the spread of anti-science misinformation and ensure transparency about how inaccurate data is analyzed.
“Despite half of U.S. and U.K. adults getting their news from social media, social media companies have not taken the steps necessary to fight industry-backed deception,” reads the report. “In fact, they continue to allow these climate lies to pollute users’ feeds.
⚠️NEW RESEARCH: Fossil fuel industry-backed climate disinformation pollutes our social media feeds and fans the flames of the #ClimateCrisis. This is why tech companies must take responsibility and stop leaving the public in the dark! https://t.co/7h0rI2jAKWpic.twitter.com/rYEtNETJrY
The groups assessed five major social media platforms—Facebook, Twitter, YouTube, Pinterest, and TikTok—and found that the two best-performing companies, Pinterest and YouTube, scored 14 out of the 27 possible points.
As Common Dreams reported earlier this month, Pinterest has won praise from groups including FOE for establishing “clearly defined guidelines against false or misleading climate change information, including conspiracy theories, across content and ads.”
“One of the key objectives of this report is to allow for fact-based deliberation, discussion, and debate to flourish in an information ecosystem that is healthy and fair, and that allows both citizens and policymakers to make decisions based on the best available data.”
The company also garnered points in Wednesday’s report for being the only major social media platform to make clear the average time or views it allows for a piece of scientifically inaccurate content before it will take action to combat the misinformation and including “omission or cherry-picking” of data in its definition of mis- or disinformation.
Pinterest and YouTube were the only companies that won points for consulting with climate scientists to develop a climate mis- and disinformation policy.
The top-performing companies, however, joined the other firms in failing to articulate exactly how their misinformation policy is enforced and to detail how climate misinformation is prioritized for fact-checking.
“Social media companies are largely leaving the public in the dark about their efforts to combat the problem,” the report reads. “There is a gross lack of transparency, as these companies conceal much of the data about the prevalence of digital climate dis/misinformation and any internal measures taken to address its spread.”
Twitter was the worst-performing company, meeting only five of the 27 criteria.
“Twitter is not clear about how content is verified as dis/misinformation, nor explicit about engaging with climate experts to review dis/misinformation policies or flagged content,” reads the report. “Twitter’s total lack of reference to climate dis/misinformation, both in their policies and throughout their enforcement reports, earned them no points in either category.”
TikTok scored seven points, while Facebook garnered nine.
The report, using criteria developed by the Climate Disinformation Coalition, was released three weeks after NPRreported that inaccurate information about renewable energy sources has been disseminated widely in Facebook groups, and the spread has been linked to slowing progress on or shutting down local projects.
In rural Ohio, posts in two anti-wind power Facebook groups spread misinformation about wind turbines causing birth defects in horses, failing to reduce carbon emissions, and causing so-called “wind turbine syndrome” from low-frequency sounds—a supposed ailment that is not backed by scientific evidence. The posts increased “perceptions of human health and public safety risks related to wind” power, according to a study published last October in the journal Energy Research & Social Science.
As those false perceptions spread through the local community, NPRreported, the Ohio Power Siting Board rejected a wind farm proposal “citing geological concerns and the local opposition.”
Misinformation on social media “can really slow down the clean energy transition, and that has just as dire life and death consequences, not just in terms of climate change, but also in terms of air pollution, which overwhelmingly hits communities of color,” University of California, Santa Barbara professor Leah Stokes told NPR.
As the IPCC reported in its February report, “rhetoric and misinformation on climate change and the deliberate undermining of science have contributed to misperceptions of the scientific consensus, uncertainty, disregarded risk and urgency, and dissent.”
Wednesday’s report called on all social media companies to:
Establish, disclose, and enforce policies to reduce climate change dis- and misinformation;
Release in full the company’s current labeling, fact-checking, policy review, and algorithmic ranking systems related to climate change disinformation policies;
Disclose weekly reports on the scale and prevalence of climate change dis- and misinformation on the platform and mitigation efforts taken internally; and
Adopt privacy and data protection policies to protect individuals and communities who may be climate dis/misinformation targets.
“One of the key objectives of this report is to allow for fact-based deliberation, discussion, and debate to flourish in an information ecosystem that is healthy and fair, and that allows both citizens and policymakers to make decisions based on the best available data,” reads the report.
“We see a clear boundary between freedom of speech and freedom of reach,” it continues, “and believe that transparency on climate dis/misinformation and accountability for the actors who spread it is a precondition for a robust and constructive debate on climate change and the response to the climate crisis.”
The new law “will put an end to some of the most harmful practices of Big Tech and narrow the power imbalance between people and online platforms.”
Digital and consumer rights advocates on Friday hailed a landmark European Union law aimed at curbing Big Tech’s monopolistic behavior.
“This is a big moment for consumers and businesses who have suffered from Big Tech’s harmful practices.”
Negotiators from the European Parliament and European Council agreed late Thursday on the language of the Digital Markets Act (DMA), which aims to prevent major tech companies from anti-competitive practices by threatening large fines or possible breakup.
Ursula Pachl, deputy director-general at the European Consumer Organization (BEUC), an umbrella advocacy group, said in a statement that “this is a big moment for consumers and businesses who have suffered from Big Tech’s harmful practices.”
“This legislation will rebalance digital markets, increase consumer choice, and put an end to many of the worst practices that Big Tech has engaged in over the years,” she added. “It is a landmark law for the E.U.’s digital transformation.”
The European Union just struck an important deal on the Digital Markets Act, recognizing that only a just and interoperable market can ensure fair competition and more choice for users. #DMAhttps://t.co/lGcTDstagj
Cédric O, the French minister of state with responsibility for digital, said in a statement that “the European Union has had to impose record fines over the past 10 years for certain harmful business practices by very large digital players. The DMA will directly ban these practices and create a fairer and more competitive economic space for new players and European businesses.”
“These rules are key to stimulating and unlocking digital markets, enhancing consumer choice, enabling better value sharing in the digital economy, and boosting innovation,” he added.
Andreas Schwab, a member of the European Parliament from Germany, said that “the Digital Markets Act puts an end to the ever-increasing dominance of Big Tech companies. From now on, Big Tech companies must show that they also allow for fair competition on the internet. The new rules will help enforce that basic principle.”
BEUC’s Pachl offered examples of the new law’s benefits:
Google must stop promoting its own local, travel, or job services over those of competitors in Google Search results, while Apple will be unable to force users to use its payment service for app purchases. Consumers will also be able to collectively enforce their rights if a company breaks the rules in the Digital Markets Act.
Companies are also barred from pre-installing certain software and reusing certain private data collected “during a service for the purposes of another service.”
Today’s historical agreement on the #DMA taught us two things, first, that the EU is up to the challenge to reign big tech and, secondly, that Europe’s civil society can make a difference in making the regulatory framework more user-focused.
The DMA applies to companies deemed both “platforms” and “gatekeepers”—those with market capitalization greater than €75 billion ($82.4 billion), 45 million or more monthly end-users, and at least 10,000 E.U. business users. Companies that violate the law can be fined up to 10% of their total annual worldwide turnover, with repeat offenders subject to a doubling of the penalty.
“The DMA is a major step towards limiting the tremendous market power that today’s gatekeeper tech firms have.”
Diego Naranjo, head of policy at the advocacy group European Digital Rights (EDRi), said in a statement that “the DMA will put an end to some of the most harmful practices of Big Tech and narrow the power imbalance between people and online platforms. If correctly implemented, the new agreement will empower individuals to choose more freely the type of online experience and society we want to build in the digital era.”
To ensure effective implementation, BEUC’s Pachl called on E.U. member states to “now also provide the [European] Commission with the necessary enforcement resources to step in the moment there is foul play.”
EDRi senior policy adviser Jan Penfrat said that while “the DMA is a major step towards limiting the tremendous market power that today’s gatekeeper tech firms have,” policymakers “must now make sure that the new obligations not to reuse personal data and the prohibition of using sensitive data for surveillance advertising are respected and properly enforced by the European Commission.”
“Only then will the change be felt by people who depend on digital services every day,” he added.
Originally published on Common Dreams by BRETT WILKINS and republished under Creative Commons (CC BY-NC-ND 3.0).
Governments increasingly use algorithms to do everything from assign benefits to dole out punishment—but attempts to regulate them have been unsuccessful
In 2018, the New York City Council created a task force to study the city’s use of automated decision systems (ADS). The concern: Algorithms, not just in New York but around the country, were increasingly being employed by government agencies to do everything from informing criminal sentencing and detecting unemployment fraud to prioritizing child abuse cases and distributing health benefits. And lawmakers, let alone the people governed by the automated decisions, knew little about how the calculations were being made.
Rare glimpses into how these algorithms were performing were not comforting: In several states, algorithms used to determine how much help residents will receive from home health aides have automatically cut benefits for thousands. Police departments across the country use the PredPol software to predict where future crimes will occur, but the program disproportionately sends police to Black and Hispanic neighborhoods. And in Michigan, an algorithm designed to detect fraudulent unemployment claims famously improperly flagged thousands of applicants, forcing residents who should have received assistance to lose their homes and file for bankruptcy.
New York City’s was the first legislation in the country aimed at shedding light on how government agencies use artificial intelligence to make decisions about people and policies.
At the time, the creation of the task force was heralded as a “watershed” moment that would usher in a new era of oversight. And indeed, in the four years since, a steady stream of reporting about the harms caused by high-stakes algorithms has prompted lawmakers across the country to introduce nearly 40 bills designed to study or regulate government agencies’ use of ADS, according to The Markup’s review of state legislation.
The bills range from proposals to create study groups to requiring agencies to audit algorithms for bias before purchasing systems from vendors. But the dozens of reforms proposed have shared a common fate: They have largely either died immediately upon introduction or expired in committees after brief hearings, according to The Markup’s review.
In New York City, that initial working group took two years to make a set of broad, nonbinding recommendations for further research and oversight. One task force member described the endeavor as a “waste.” The group could not even agree on a definition for automated decision systems, and several of its members, at the time and since, have said they did not believe city agencies and officials had bought into the process.
Elsewhere, nearly all proposals to study or regulate algorithms have failed to pass. Bills to create study groups to examine the use of algorithms failed in Massachusetts, New York state, California, Hawaii, and Virginia. Bills requiring audits of algorithms or prohibiting algorithmic discrimination have died in California, Maryland, New Jersey, and Washington state. In several cases—California, New Jersey, Massachusetts, Michigan, and Vermont—ADS oversight or study bills remain pending in the legislature, but their prospects this session are slim, according to sponsors and advocates in those states.
The only state bill to pass so far, Vermont’s, created a task force whose recommendations—to form a permanent AI commission and adopt regulations—have so far been ignored, state representative Brian Cina told The Markup.
The Markup interviewed lawmakers and lobbyists and reviewed written and oral testimony on dozens of ADS bills to examine why legislatures have failed to regulate these tools.
We found two key through lines: Lawmakers and the public lack fundamental access to information about what algorithms their agencies are using, how they’re designed, and how significantly they influence decisions. In many of the states The Markup examined, lawmakers and activists said state agencies had rebuffed their attempts to gather basic information, such as the names of tools being used.
Meanwhile, Big Tech and government contractors have successfully derailed legislation by arguing that proposals are too broad—in some cases claiming they would prevent public officials from using calculators and spreadsheets—and that requiring agencies to examine whether an ADS system is discriminatory would kill innovation and increase the price of government procurement.
Lawmakers Struggled to Figure Out What Algorithms Were Even in Use
One of the biggest challenges lawmakers have faced when seeking to regulate ADS tools is simply knowing what they are and what they do.
Following its task force’s landmark report, New York City conducted a subsequent survey of city agencies. It resulted in a list of only 16 automated decision systems across nine agencies, which members of the task force told The Markup they suspect is a severe underestimation.
“We don’t actually know where government entities or businesses use these systems, so it’s hard to make [regulations] more concrete,” said Julia Stoyanovich, a New York University computer science professor and task force member.
In 2018, Vermont became the first state to create its own ADS study group. At the conclusion of its work in 2020, the group reported that “there are examples of where state and local governments have used artificial intelligence applications, but in general the Task Force has not identified many of these applications.”
“Just because nothing popped up in a few weeks of testimony doesn’t mean that they don’t exist,” said Cina. “It’s not like we asked every single state agency to look at every single thing they use.”
In February, he introduced a bill that would have required the state to develop basic standards for agency use of ADS systems. It has sat in committee without a hearing since then.
In 2019, the Hawaii Senate passed a resolution requesting that the state convene a task force to study agency use of artificial intelligence systems, but the resolution was nonbinding and no task force convened, according to the Hawaii Legislative Reference Bureau. Legislators tried to pass a binding resolution again the next year, but it failed.
Legislators and advocacy groups who authored ADS bills in California, Maryland, Massachusetts, Michigan, New York, and Washington told The Markup that they have no clear understanding of the extent to which their state agencies use ADS tools.
Advocacy groups like the Electronic Privacy Information Center (EPIC) that have attempted to survey government agencies regarding their use of ADS systems say they routinely receive incomplete information.
“The results we’re getting are straight-up non-responses or truly pulling teeth about every little thing,” said Ben Winters, who leads EPIC’s AI and Human Rights Project.
In Washington, after an ADS regulation bill failed in 2020, the legislature created a study group tasked with making recommendations for future legislation. The ACLU of Washington proposed that the group should survey state agencies to gather more information about the tools they were using, but the study group rejected the idea, according to public minutes from the group’s meetings.
“We thought it was a simple ask,” said Jennifer Lee, the technology and liberty project manager for the ACLU of Washington. “One of the barriers we kept getting when talking to lawmakers about regulating ADS is they didn’t have an understanding of how prevalent the issue was. They kept asking, ‘What kind of systems are being used across Washington state?’ ”
Ben Winters, who leads EPIC’s AI and Human Rights Project
Lawmakers Say Corporate Influence a Hurdle
Washington’s most recent bill has stalled in committee, but an updated version will likely be reintroduced this year now that the study group has completed its final report, said state senator Bob Hasegawa, the bill’s sponsor
The legislation would have required any state agency seeking to implement an ADS system to produce an algorithmic accountability report disclosing the name and purpose of the system, what data it would use, and whether the system had been independently tested for biases, among other requirements.
The bill would also have banned the use of ADS tools that are discriminatory and required that anyone affected by an algorithmic decision be notified and have a right to appeal that decision.
“The big obstacle is corporate influence in our governmental processes,” said Hasegawa. “Washington is a pretty high-tech state and so corporate high tech has a lot of influence in our systems here. That’s where most of the pushback has been coming from because the impacted communities are pretty much unanimous that this needs to be fixed.”
California’s bill, which is similar, is still pending in committee. It encourages, but does not require, vendors seeking to sell ADS tools to government agencies to submit an ADS impact report along with their bid, which would include similar disclosures to those required by Washington’s bill.
It would also require the state’s Department of Technology to post the impact reports for active systems on its website.
Led by the California Chamber of Commerce, 26 industry groups—from big tech representatives like the Internet Association and TechNet to organizations representing banks, insurance companies, and medical device makers—signed on to a letter opposing the bill.
“There are a lot of business interests here, and they have the ears of a lot of legislators,” said Vinhcent Le, legal counsel at the nonprofit Greenlining Institute, who helped author the bill.
Originally, the Greenlining Institute and other supporters sought to regulate ADS in the private sector as well as the public but quickly encountered pushback.
“When we narrowed it to just government AI systems we thought it would make it easier,” Le said. “The argument [from industry] switched to ‘This is going to cost California taxpayers millions more.’ That cost angle, that innovation angle, that anti-business angle is something that legislators are concerned about.”
The California Chamber of Commerce declined an interview request for this story but provided a copy of the letter signed by dozens of industry groups opposing the bill. The letter states that the bill would “discourage participation in the state procurement process” because the bill encourages vendors to complete an impact assessment for their tools. The letter said the suggestion, which is not a requirement, was too burdensome. The chamber also argued that the bill’s definition of automated decision systems was too broad.
Industry lobbyists have repeatedly criticized legislation in recent years for overly broad definitions of automated decision systems despite the fact that the definitions mirror those used in internationally recognized AI ethics frameworks, regulations in Canada, and proposed regulations in the European Union.
During a committee hearing on Washington’s bill, James McMahan, policy director for the Washington Association of Sheriffs and Police Chiefs, told legislators he believed the bill would apply to “most if not all” of the state crime lab’s operations, including DNA, fingerprint, and firearm analysis.
Internet Association lobbyist Vicki Christophersen, testifying at the same hearing, suggested that the bill would prohibit the use of red light cameras. The Internet Association did not respond to an interview request.
“It’s a funny talking point,” Le said. “We actually had to put in language to say this doesn’t include a calculator or spreadsheet.”
Maryland’s bill, which died in committee, would also have required agencies to produce reports detailing the basic purpose and functions of ADS tools and would have prohibited the use of discriminatory systems.
“We’re not telling you you can’t do it [use ADS],” said Delegate Terri Hill, who sponsored the Maryland bill. “We’re just saying identify what your biases are up front and identify if they’re consistent with the state’s overarching goals and with this purpose.”
The Maryland Tech Council, an industry group representing small and large technology firms in the state, opposed the bill, arguing that the prohibitions against discrimination were premature and would hurt innovation in the state, according to written and oral testimony the group provided.
“The ability to adequately evaluate whether or not there is bias is an emerging area, and we would say that, on behalf of the tech council, putting in place this at this time is jumping ahead of where we are,” Pam Kasemeyer, the council’s lobbyist, said during a March committee hearing on the bill. “It almost stops the desire for companies to continue to try to develop and refine these out of fear that they’re going to be viewed as discriminatory.”
Limited Success in the Private Sector
There have been fewer attempts by state and local legislatures to regulate private companies’ use of ADS systems—such as those The Markup has exposed in the tenant screening and car insurance industries—but in recent years, those measures have been marginally more successful.
The New York City Council passed a bill that would require private companies to conduct bias audits of algorithmic hiring tools before using them. The tools are used by many employers to screen job candidates without the use of a human interviewer.
Illinois also enacted a state law in 2019 that requires private employers to notify job candidates when they’re being evaluated by algorithmic hiring tools. And in 2021, the legislature amended the law to require employers who use such tools to report demographic data about job candidates to a state agency to be analyzed for evidence of biased decisions.
This year the Colorado legislature also passed a law, which will take effect in 2023, that will create a framework for evaluating insurance underwriting algorithms and ban the use of discriminatory algorithms in the industry.
CEO Mark Zuckerberg had repeatedly promised to stop recommending political groups to users to squelch the spread of misinformation
Leaked internal Facebook documents show that a combination of technical miscommunications and high-level decisions led to one of the social media giant’s biggest broken promises of the 2020 election—that it would stop recommending political groups to users.
The Markup first revealed on Jan. 19 that Facebook was continuing to recommend political groups—including some in which users advocated violence and storming the U.S. Capitol—in spite of multiple promises not to do so, including one made under oath to Congress.
The day the article ran, a Facebook team started investigating the “leakage,” according to documents provided by Frances Haugen to Congress and shared with The Markup, and the problem was escalated to the highest level to be “reviewed by Mark.” Over the course of the next week, Facebook employees identified several causes for the broken promise.
The company, according to work log entries in the leaked documents, was updating its list of designated political groups, which it refers to as civic groups, in real time. But the systems that recommend groups to users were cached on servers and users’ devices and only updated every 24 to 48 hours in some cases. The lag resulted in users receiving recommendations for groups that had recently been designated political, according to the logs.
That technical oversight was compounded by a decision Facebook officials made about how to determine whether or not a particular group was political in nature.
When The Markup examined group recommendations using data from our Citizen Browser project—a paid, nationwide panel of Facebook users who automatically supply us data from their Facebook feeds—we designated groups as political or not based on their names, about pages, rules, and posted content. We found 12 political groups among the top 100 groups most frequently recommended to our panelists.
Facebook chose to define groups as political in a different way—by looking at the last seven days’ worth of content in a given group.
“Civic filter uses last 7 day content that is created/viewed in the group to determine if the group is civic or not,” according to a summary of the problem written by a Facebook employee working to solve the issue.
As a result, the company was seeing a “12% churn” in its list of groups designated as political. If a group went seven days without posting content the company’s algorithms deemed political, it would be taken off the blacklist and could once again be recommended to users.
Almost 90 percent of the impressions—the number of times a recommendation was seen—on political groups that Facebook tallied while trying to solve the recommendation problem were a result of the day-to-day turnover on the civic group blacklist, according to the documents.
Facebook did not directly respond to questions for this story.
“We learned that some civic groups were recommended to users, and we looked into it,” Facebook spokesperson Leonard Lam wrote in an email to The Markup. “The issue stemmed from the filtering process after designation that allowed some Groups to remain in the recommendation pool and be visible to a small number of people when they should not have been. Since becoming aware of the issue, we worked quickly to update our processes, and we continue this work to improve our designation and filtering processes to make them as accurate and effective as possible.”
Social networking and misinformation researchers say that the company’s decision to classify groups as political based on seven days’ worth of content was always likely to fall short.
“They’re definitely going to be missing signals with that because groups are extremely dynamic,” said Jane Lytvynenko, a research fellow at the Harvard Shorenstein Center’s Technology and Social Change Project. “Looking at the last seven days, rather than groups as a whole and the stated intent of groups, is going to give you different results. It seems like maybe what they were trying to do is not cast too wide of a net with political groups.”
Many of the groups Facebook recommended to Citizen Browser users had overtly political names.
More than 19 percent of Citizen Browser panelists who voted for Donald Trump received recommendations for a group called Candace Owens for POTUS, 2024, for example. While Joe Biden voters were less likely to be nudged toward political groups, some received recommendations for groups like Lincoln Project Americans Protecting Democracy.
The internal Facebook investigation into the political recommendations confirmed these problems. By Jan. 25, six days after The Markup’s original article, a Facebook employee declared that the problem was “mitigated,” although root causes were still under investigation.
On Feb. 10, Facebook blamed the problem on “technical issues” in a letter it sent to U.S. senator Ed Markey, who had demanded an explanation.
In the early days after the company’s internal investigation, the issue appeared to have been resolved. Both Citizen Browser and Facebook’s internal data showed that recommendations for political groups had virtually disappeared.
But when The Markup reexamined Facebook’s recommendations in June, we discovered that the platform was once again nudging Citizen Browser users toward political groups, including some in which members explicitly advocated violence.
From February to June, just under one-third of Citizen Browser’s 2,315 panelists received recommendations to join a political group. That included groups with names like Progressive Democrats of Nevada, Michigan Republicans, Liberty lovers for Ted Cruz, and Bernie Sanders for President, 2020.
Facebook insists that mainstream news sites perform the best on its platform. But by other measures, sensationalist, partisan content reigns
In early November, Facebook published its Q3 Widely Viewed Content Report, the second in a series meant to rebut critics who said that its algorithms were boosting extremist and sensational content. The report declared that, among other things, the most popular informational content on Facebook came from sources like UNICEF, ABC News, or the CDC.
But data collected by The Markup suggests that, on the contrary, sensationalist news or viral content with little original reporting performs just as well as—and often better than—many mainstream sources when it comes to how often it’s seen by platform users.
Data from The Markup’s Citizen Browser project shows that during the period from July 1 to Sept. 30, 2021, outlets like The Daily Wire, The Western Journal, and BuzzFeed’s viral content arm were among the top-viewed domains in our sample.
Citizen Browser is a national panel of paid Facebook users who automatically share their news feed data with The Markup.
To analyze the websites whose content performs the best on Facebook, we counted the total number of times that links from any domain appeared in our panelists’ news feeds—a metric known as “impressions”—over a three-month period (the same time covered by Facebook’s Q3 Widely Viewed Content Report). Facebook, by contrast, chose a different metric, calculating the “most-viewed” domains by tallying only the number of users who saw links, regardless of whether each user saw a link once or hundreds of times.
By our calculation, the top performing domains were those that surfaced in users’ feeds over and over—including some highly partisan, polarizing sites that effectively bombarded some Facebook users with content.
These findings chime with recent revelations from Facebook whistleblower Frances Haugen, who has repeatedly said the company has a tendency to cherry-pick statistics to release to the press and the public.
When presented with The Markup’s findings and asked whether its own report’s statistics might be misleading or incomplete, Ariana Anthony, a spokesperson for Meta, Facebook’s parent company, said in an emailed statement, “The focus of the Widely Viewed Content Report is to show the content that is seen by the most people on Facebook, not the content that is posted most frequently. That said, we will continue to refine and improve these reports as we engage with academics, civil society groups, and researchers to identify the parts of these reports they find most valuable, which metrics need more context, and how we can best support greater understanding of content distribution on Facebook moving forward.”
Anthony did not directly respond to questions from The Markup on whether the company would release data on the total number of link views or the content that was seen most frequently on the platform.
The Battle Over Data
There are many ways to measure popularity on Facebook, and each tells a different story about the platform and what kind of content its algorithms favor.
For years, the startup CrowdTangle’s “engagement” metric—essentially measuring a combination of how many likes, comments, and other interactions any domain’s posts garner—has been the most publicly visible way of measuring popularity. Facebook bought CrowdTangle in 2016 and, according to reporting in The New York Times, has since largely tried to downplay data showing that ultra-conservative commentators like The Daily Wire’s Ben Shapiro produce the most engaged-with content on the platform.
Shortly after the end of the second quarter of this year, Facebook came out with its first transparency report, framed in the introduction as a way to “provide clarity” on “the most-viewed domains, links, Pages and posts on the platform during the quarter.” (More accurately, the Q2 report was the first publicly released transparency report, after a Q1 report was, The New York Times reported, suppressed for making the company look bad and only released later after details emerged.)
For the Q2 and Q3 reports, Facebook turned to a specific metric, known as “reach,” to quantify most-viewed domains. For any given domain, say youtube.com or twitter.com, reach represents the number of unique Facebook accounts that had at least one post containing a link to a tweet or a YouTube video in their news feeds during the quarter. On that basis, Facebook found that those domains, and other mainstream staples like Amazon, Spotify, and TikTok, had wide reach.
When applying this metric, The Markup found similar results in our Citizen Browser data, as detailed in depth in our methodology. But this calculation ignores a reality for a lot of Facebook users: bombardment with content from the same site.
Citizen Browser data shows, for instance, that from July through September of this year, articles from far-right news site Newsmax appeared in the feed of a 58-year-old woman in New Mexico 1,065 times—but under Facebook’s calculation of reach, this would count as one single unit. Similarly, a 37-year-old man in New Hampshire was shown 245 unique links to satirical posts from The Onion, which appeared in his feed more than 500 times—but again, he would have been counted just once by Facebook’s method.
When The Markup instead counted each appearance of a domain on a user’s feed during Q3—e.g., Newsmax as 1,065 instead of 1—we found that polarizing, partisan content jumped in the performance rankings. Indeed, the same trend is true of the domains in Facebook’s Q2 report, for which analysis can be found in our data repository on GitHub.
We found that outlets like The Daily Wire, BuzzFeed’s viral content arm, Fox News, and Yahoo News jumped in the popularity rankings when we used the impressions metric. Most striking, The Western Journal—which, similarly to The Daily Wire, does little original reporting and instead repackages stories to fit with right-wing narratives—improved its ranking by almost 200 places.
“To me these findings raise a number of questions,” said Jane Lytvynenko, senior research fellow at the Harvard Kennedy School Shorenstein Center.
“Was Facebook’s research genuine, or was it part of an attempt to change the narrative around top 10 lists that were previously put out? It matters a lot whether a person sees a link one time or if they see it 20 times, and to not account for that in a report, to me, is misleading,” Lytvynenko said.
Using a narrow range of data to gauge popularity is suspect, said Alixandra Barasch, associate professor of marketing at NYU’s Stern School of Business.
“It just goes against everything we teach and know about advertising to focus on one [metric] rather than the other,” she said.
In fact, when it comes to the core business model of selling space to advertisers, Facebook encourages them to consider yet another metric, “frequency”—how many times to show a post to each user on average—when trying to optimize brand messaging.
Data from Citizen Browser shows that domains seen with high frequency in the Facebook news feed are mostly news domains, since news websites tend to publish multiple articles over the course of a day or week. But Facebook’s own content report does not take this data into account.
“[This] clarifies the point that what we need is independent access for researchers to check the math,” said Justin Hendrix, co-author of a report on social media and polarization and editor at Tech Policy Press, after reviewing The Markup’s data.
Leaked internal documents suggest Facebook – which recently renamed itself Meta – is doing far worse than it claims at minimizing COVID-19 vaccine misinformation on the Facebook social media platform.
Online misinformation about the virus and vaccines is a major concern. In one study, survey respondents who got some or all of their news from Facebook were significantly more likely to resist the COVID-19 vaccine than those who got their news from mainstream media sources.
As a researcher who studies social and civic media, I believe it’s critically important to understand how misinformation spreads online. But this is easier said than done. Simply counting instances of misinformation found on a social media platform leaves two key questions unanswered: How likely are users to encounter misinformation, and are certain users especially likely to be affected by misinformation? These questions are the denominator problem and the distribution problem.
The COVID-19 misinformation study, “Facebook’s Algorithm: a Major Threat to Public Health”, published by public interest advocacy group Avaaz in August 2020, reported that sources that frequently shared health misinformation — 82 websites and 42 Facebook pages — had an estimated total reach of 3.8 billion views in a year.
At first glance, that’s a stunningly large number. But it’s important to remember that this is the numerator. To understand what 3.8 billion views in a year means, you also have to calculate the denominator. The numerator is the part of a fraction above the line, which is divided by the part of the fraction below line, the denominator.
Getting some perspective
One possible denominator is 2.9 billion monthly active Facebook users, in which case, on average, every Facebook user has been exposed to at least one piece of information from these health misinformation sources. But these are 3.8 billion content views, not discrete users. How many pieces of information does the average Facebook user encounter in a year? Facebook does not disclose that information.
Without knowing the denominator, a numerator doesn’t tell you very much. The Conversation U.S., CC BY-ND
Market researchers estimate that Facebook users spend from 19 minutes a day to 38 minutes a day on the platform. If the 1.93 billion daily active users of Facebook see an average of 10 posts in their daily sessions – a very conservative estimate – the denominator for that 3.8 billion pieces of information per year is 7.044 trillion (1.93 billion daily users times 10 daily posts times 365 days in a year). This means roughly 0.05% of content on Facebook is posts by these suspect Facebook pages.
The 3.8 billion views figure encompasses all content published on these pages, including innocuous health content, so the proportion of Facebook posts that are health misinformation is smaller than one-twentieth of a percent.
Is it worrying that there’s enough misinformation on Facebook that everyone has likely encountered at least one instance? Or is it reassuring that 99.95% of what’s shared on Facebook is not from the sites Avaaz warns about? Neither.
Misinformation distribution
In addition to estimating a denominator, it’s also important to consider the distribution of this information. Is everyone on Facebook equally likely to encounter health misinformation? Or are people who identify as anti-vaccine or who seek out “alternative health” information more likely to encounter this type of misinformation?
Another social media study focusing on extremist content on YouTube offers a method for understanding the distribution of misinformation. Using browser data from 915 web users, an Anti-Defamation League team recruited a large, demographically diverse sample of U.S. web users and oversampled two groups: heavy users of YouTube, and individuals who showed strong negative racial or gender biases in a set of questions asked by the investigators. Oversampling is surveying a small subset of a population more than its proportion of the population to better record data about the subset.
The researchers found that 9.2% of participants viewed at least one video from an extremist channel, and 22.1% viewed at least one video from an alternative channel, during the months covered by the study. An important piece of context to note: A small group of people were responsible for most views of these videos. And more than 90% of views of extremist or “alternative” videos were by people who reported a high level of racial or gender resentment on the pre-study survey.
While roughly 1 in 10 people found extremist content on YouTube and 2 in 10 found content from right-wing provocateurs, most people who encountered such content “bounced off” it and went elsewhere. The group that found extremist content and sought more of it were people who presumably had an interest: people with strong racist and sexist attitudes.
The authors concluded that “consumption of this potentially harmful content is instead concentrated among Americans who are already high in racial resentment,” and that YouTube’s algorithms may reinforce this pattern. In other words, just knowing the fraction of users who encounter extreme content doesn’t tell you how many people are consuming it. For that, you need to know the distribution as well.
Superspreaders or whack-a-mole?
A widely publicized study from the anti-hate speech advocacy group Center for Countering Digital Hate titled Pandemic Profiteers showed that of 30 anti-vaccine Facebook groups examined, 12 anti-vaccine celebrities were responsible for 70% of the content circulated in these groups, and the three most prominent were responsible for nearly half. But again, it’s critical to ask about denominators: How many anti-vaccine groups are hosted on Facebook? And what percent of Facebook users encounter the sort of information shared in these groups?
Without information about denominators and distribution, the study reveals something interesting about these 30 anti-vaccine Facebook groups, but nothing about medical misinformation on Facebook as a whole.
These types of studies raise the question, “If researchers can find this content, why can’t the social media platforms identify it and remove it?” The Pandemic Profiteers study, which implies that Facebook could solve 70% of the medical misinformation problem by deleting only a dozen accounts, explicitly advocates for the deplatforming of these dealers of disinformation. However, I found that 10 of the 12 anti-vaccine influencers featured in the study have already been removed by Facebook.
Consider Del Bigtree, one of the three most prominent spreaders of vaccination disinformation on Facebook. The problem is not that Bigtree is recruiting new anti-vaccine followers on Facebook; it’s that Facebook users follow Bigtree on other websites and bring his content into their Facebook communities. It’s not 12 individuals and groups posting health misinformation online – it’s likely thousands of individual Facebook users sharing misinformation found elsewhere on the web, featuring these dozen people. It’s much harder to ban thousands of Facebook users than it is to ban 12 anti-vaccine celebrities.
This is why questions of denominator and distribution are critical to understanding misinformation online. Denominator and distribution allow researchers to ask how common or rare behaviors are online, and who engages in those behaviors. If millions of users are each encountering occasional bits of medical misinformation, warning labels might be an effective intervention. But if medical misinformation is consumed mostly by a smaller group that’s actively seeking out and sharing this content, those warning labels are most likely useless.
Trying to understand misinformation by counting it, without considering denominators or distribution, is what happens when good intentions collide with poor tools. No social media platform makes it possible for researchers to accurately calculate how prominent a particular piece of content is across its platform.
Facebook restricts most researchers to its Crowdtangle tool, which shares information about content engagement, but this is not the same as content views. Twitter explicitly prohibits researchers from calculating a denominator, either the number of Twitter users or the number of tweets shared in a day. YouTube makes it so difficult to find out how many videos are hosted on their service that Google routinely asks interview candidates to estimate the number of YouTube videos hosted to evaluate their quantitative skills.
As the societal impacts of social media become more prominent, pressure on the big tech platforms to release more data about their users and their content is likely to increase. If those companies respond by increasing the amount of information that researchers can access, look very closely: Will they let researchers study the denominator and the distribution of content online? And if not, are they afraid of what researchers will find?
Facebook Inc. has rebranded itself, now, as Meta, most likely as a means to separate the corporate identity of the social network that has been tied to a myriad of ugly controversies. The name change is meant to highlight the company’s shift to virtual reality and the metaverse.
CEO Zuckerberg spoke at the Facebook’s Connect virtual conference and commented on the name change, “From now on, we’re going to be metaverse-first, not Facebook-first.”
The new name change does not affect the company’s share data or corporate structure, however the company will start trading under the new ticker, MVRS starting December 1.
Needless to say, Twitter comments and memes instantly rolled in after the rebrand announcement:
Facebook has named itself Meta, a word that means "please forget about all the leaked internal documents that are currently showing all the horrors of social media"
“This industry is rotten at its core,” said one critic, “and the clearest proof of that is what it’s doing to our children.”
Internal documents dubbed “The Facebook Papers” were published widely Monday by an international consortium of news outlets who jointly obtained the redacted materials recently made available to the U.S. Congress by company whistleblower Frances Haugen.
“It’s time for immediate action to hold the company accountable for the many harms it’s inflicted on our democracy.”
The papers were shared among 17 U.S. outlets as well as a separate group of news agencies in Europe, with all the journalists involved sharing the same publication date but performing their own reporting based on the documents.
According to the Financial Times, the “thousands of pages of leaked documents paint a damaging picture of a company that has prioritized growth” over other concerns. And the Washington Postconcluded that the choices made by founder and CEO Mark Zuckerberg, as detailed in the revelations, “led to disastrous outcomes” for the social media giant and its users.
From an overview of the documents and the reporting project by the Associated Press:
The papers themselves are redacted versions of disclosures that Haugen has made over several months to the Securities and Exchange Commission, alleging Facebook was prioritizing profits over safety and hiding its own research from investors and the public.
These complaints cover a range of topics, from its efforts to continue growing its audience, to how its platforms might harm children, to its alleged role in inciting political violence. The same redacted versions of those filings are being provided to members of Congress as part of its investigation. And that process continues as Haugen’s legal team goes through the process of redacting the SEC filings by removing the names of Facebook users and lower-level employees and turns them over to Congress.
One key revelation highlighted by the Financial Times is that Facebook has been perplexed by its own algorithms and another was that the company “fiddled while the Capitol burned” during the January 6th insurrection staged by loyalists to former President Donald Trump trying to halt the certification of last year’s election.
CNNwarned that the totality of what’s contained in the documents “may be the biggest crisis in the company’s history,” but critics have long said that at the heart of the company’s problem is the business model upon which it was built and the mentality that governs it from the top, namely Zuckerberg himself.
On Friday, following reporting based on a second former employee of the company coming forward after Haugen, Free Press Action co-CEO Jessica J. González said “the latest whistleblower revelations confirm what many of us have been sounding the alarm about for years.”
“Facebook is not fit to govern itself,” said González. “The social-media giant is already trying to minimize the value and impact of these whistleblower exposés, including Frances Haugen’s. The information these brave individuals have brought forth is of immense importance to the public and we are grateful that these and other truth-tellers are stepping up.”
While Zuckerberg has testified multiple times before Congress, González said nothing has changed. “It’s time for Congress and the Biden administration to investigate a Facebook business model that profits from spreading the most extreme hate and disinformation,” she said. “It’s time for immediate action to hold the company accountable for the many harms it’s inflicted on our democracy.”
“Kids don’t stand a chance against the multibillion dollar Facebook machine, primed to feed them content that causes severe harm to mental and physical well being.”
With Haugen set to testify before the U.K. Parliament on Monday, activists in London staged protests against Facebook and Zuckerberg, making clear that the giant social media company should be seen as a global problem.
Flora Rebello Arduini, senior campaigner with the corporate accountability group, was part of a team that erected a large cardboard display of Zuckerberg “surfing a wave of cash” outside of Parliament with a flag that read, “I know we harm kids, but I don’t care”—a rip on a video Zuckerberg posted of himself earlier this year riding a hydrofoil while holding an American flag.
While Zuckerberg refused an invitation to tesify in the U.K. about the company’s activities, including the way it manipulates and potentially harms young users on the platform, critics like Arduini said the giant tech company must be held to account.
“Kids don’t stand a chance against the multibillion dollar Facebook machine, primed to feed them content that causes severe harm to mental and physical well being,” she said. “This industry is rotten at its core and the clearest proof of that is what it’s doing to our children. Lawmakers must urgently step in and pull the tech giants into line.”
Happening now: we are outside UK parliament with a visual protest against Facebook’s treatment of children and its business model which puts profit before public safety. (1/7) #PeopleVsBigTechpic.twitter.com/37UA18PL3r
“Right now, Mark [Zuckerberg] is unaccountable,” Haugen told the Guardian in an interview ahead of her testimony. “He has all the control. He has no oversight, and he has not demonstrated that he is willing to govern the company at the level that is necessary for public safety.”
Correction: This article has been updated to more accurately reflect the context of the comments made by Jessica González of Free Press, who responded to the revelations of a second whistleblower not those of Frances Haugen.
Originally published on Common Dreams by JON QUEALLY and republished under a Creative Commons License (CC BY-NC-ND 3.0).
Frances Haugen said the company’s leaders know how to make their platforms safer, “but won’t make the necessary changes because they have put their astronomical profits before people.
Two days after a bombshell “60 Minutes” interview in which she accused Facebook of knowingly failing to stop the spread of dangerous lies andhateful content, whistleblower Frances Haugen testified Tuesday before U.S. senators, imploring Congress to hold the company and its CEO accountable for the many harms they cause.
Haugen—a former Facebook product manager—told the senators she went to work at the social media giant because she believed in its “potential to bring out the best in us.”
“But I’m here today because I believe Facebook’s products harm children, stoke division, and weaken our democracy,” she said during her opening testimony. “The company’s leadership knows how to make Facebook and Instagram safer, but won’t make the necessary changes because they have put their astronomical profits before people.”
“The documents I have provided to Congress prove that Facebook has repeatedly misled the public about what its own research reveals about the safety of children, the efficacy of its artificial intelligence systems, and its role in spreading divisive and extreme messages,” she continued. “I came forward because I believe that every human being deserves the dignity of truth.”
Facebook whistleblower Frances Haugen: "I saw Facebook repeatedly encounter conflicts between its own profits and our safety. Facebook consistently resolved its conflicts in favor of its own profits."
“I saw Facebook repeatedly encounter conflicts between its own profits and our safety,” Haugen added. “Facebook consistently resolved its conflicts in favor of its own profits.”
“In some cases, this dangerous online talk has led to actual violence that harms and even kills people,” she said.
Addressing Monday’s worldwide Facebook outage, Haugen said that “for more than five hours, Facebook wasn’t used to deepen divides, destabilize democracies, and make young girls and women feel bad about their bodies.”
“It also means that millions of small businesses weren’t able to reach potential customers, and countless photos of new babies weren’t joyously celebrated by family and friends around the world,” she added. “I believe in the potential of Facebook. We can have social media we enjoy that connects us without tearing apart our democracy, putting our children in danger, and sowing ethnic violence around the world. We can do better.”
Doing better will require Congress to act, because Facebook “won’t solve this crisis without your help,” Haugen told the senators, echoing experts and activists who continue to call for breaking up tech giants, banning the surveillance capitalist business model, and protecting rights and democracy online.
She added that “there is nobody currently holding Zuckerberg accountable but himself,” referring to Facebook co-founder and CEO Mark Zuckerberg.
Sen. Richard Blumenthal (D-Conn.)—chair of the Senate Consumer Protection, Product Safety, and Data Security Subcommittee—called on Zuckerberg to testify before the panel.
“Mark Zuckerberg ought to be looking at himself in the mirror today and yet rather than taking responsibility, and showing leadership, Mr. Zuckerberg is going sailing,” he said.
Frances Haugen strongly shakes her head in agreement as Richard Blumenthal says "Mark Zuckerberg ought to be looking at himself in the mirror" and "Zuckerberg, you need to come before this committee." pic.twitter.com/QC0B6zK9tW
“Big Tech now faces a Big Tobacco, jaw-dropping moment of truth. It is documented proof that Facebook knows its products can be addictive and toxic to children,” Blumenthal continued.
“The damage to self-interest and self-worth inflicted by Facebook today will haunt a generation,” he added. “Feelings of inadequacy and insecurity, rejection, and self-hatred will impact this generation for years to come. Our children are the ones who are victims.”
Originally published on Common Dreams by BRETT WILKINSand republished under Creative Commons (CC BY-NC-ND 3.0).
The tweak, which targets the code in accessibility features for visually impaired users, drew ire from researchers and those who monitor the platform
Facebook has begun rolling out an update that is interfering with watchdogs monitoring the platform.
The Markup has found evidence that Facebook is adding changes to its website code that foils automated data collection of news feed posts—a technique that groups like NYU’s Ad Observatory, The Markup, and other researchers and journalists use to audit what’s happening on the platform on a large scale.
The changes, which attach junk code to HTML features meant to improve accessibility for visually impaired users, also impact browser-based ad blocking services on the platform. The new code risks damaging the user experience for people who are visually impaired, a group that has struggled to use the platform in the past.
The updates add superfluous text to news feed posts in the form of ARIA tags, an element of HTML code that is not rendered visually by a standard web browser but is used by screen reader software to map the structure and read aloud the contents of a page. Such code is also used by organizations like NYU’s Ad Observatory to identify sponsored posts on the platform and weed them out for further scrutiny.
“We constantly make code changes across our services, but we did not make any code changes to block these research projects,” Lindy Wagner, communications manager at Facebook, said in an email to The Markup.
Following the changes, the Citizen Browser project experienced a drop in data collection rates from early September, prompting the investigation that uncovered these changes to the code. At around the same time, users of certain ad blockers noticed a decrease in their effectiveness.
Laura Edelson, a Ph.D. candidate in computer science at NYU’s Tandon School of Engineering and founder of the Ad Observatory project, expressed dismay at Facebook’s latest move impacting data collection. The website update had at first caused a sharp drop in the amount of data collected by the Ad Observatory, she said, but a fix was found that allowed the team to collect data at normal levels.
“I think it’s unfortunate that Facebook is continuing to fight with researchers rather than work with them,” she said.
Facebook has used similar tweaks to attempt to frustrate researchers and ad blockers in the past, often with the result of making the platform less accessible to visually impaired users.
In 2019, the company made changes to obfuscate its code in a way that blocked ad collection efforts by ProPublica, Mozilla, and British ad transparency group WhoTargetsMe. And in 2020, Quartz reported that visually impaired users had been unable to hear a legible label distinguishing between sponsored and nonsponsored posts for the previous two years because the platform had added numerous junk characters to the text to reduce the efficiency of ad blocking software.
In its latest update, Facebook seems to have implemented the code in a way that prevents screen readers from reading the new tags. As the update has not yet been rolled out to all users, it’s unclear what, if any, impact the change may have on visually impaired users. In at least one circumstance, a developer from The Markup who was testing the new code found that the Microsoft Narrator screen reader read aloud a string of junk characters as an unintelligible word when accessing the site through the Google Chrome browser.
“Our accessibility features largely appear to be working as normal, however we are investigating the claim,” Facebook’s Wagner said.
Jared Smith, associate director of accessibility research and training nonprofit WebAIM, expressed concerns about the code in Facebook’s web update after reviewing it for The Markup.
According to Smith, the new updates break many basic rules of accessibility design. Rather than presenting a clear and simplified structure, he said, the accessibility code was hugely complex, potentially heralding problems down the road.
“When you see thousands and thousands of patterns of ARIA attributes—code that could be used for accessibility but doesn’t seem to support accessibility—it poses a scenario where things could jump the rails and really negatively impact accessibility,” said Smith.
“We’ve seen misuse of technologies like this for things like search engine optimization, but this is on an entirely different scale,” he added.
In July 2020, a blog post from the Facebook engineering team trumpeted an extensive rebuild of the site that was apparently made with accessibility in mind. This included requirements for Facebook developers to use a code linting plugin (similar to a spelling autocorrect) that would highlight violations of ARIA standards.
“I suspect that the Facebook team implementing these apparent anti-transparency mechanisms does not realize that there are potential accessibility consequences to what they’re doing,” said Blake E. Reid, a professor at the University of Colorado Law School who focuses on accessibility and technology policy.
Sen. Ron Wyden, who has been critical of the company in the past, told The Markup in an emailed statement that Facebook’s latest move showed a disregard for visually impaired users.
“It is contemptible that Facebook would misuse accessibility features for users with disabilities just to foil legitimate research and journalism,” he said.
Facebook has long claimed that it wants to share data with researchers, Edelson said, but in practice numerous social scientists have faced obstacles when trying to work with the platform.
In August of this year, Facebook disabled the accounts of NYU Ad Observatory researchers for alleged violations of its terms of service with the researchers’ own ad collector. (At the time, The Markup’s senior executives published a press release critical of Facebook’s actions.)
And reporting by The New York Times brought to light the fact that Facebook had given incomplete data to misinformation researchers from the high profile Social Science One research group, potentially undermining the findings of years of academic studies. The error was first uncovered by a university professor who found discrepancies between numbers in the Social Science One data and Facebook’s recently published Widely Viewed Content Report.
“At what point does the research community stop thinking of Facebook as a positive actor in this space?” Edelson said.
Experts say the privacy promise—ubiquitous in online services and apps—obscures the truth about how companies use personal data
You’ve likely run into this claim from tech giants before: “We do not sell your personal data.”
Companies from Facebook to Google to Twitter repeat versions of this statement in their privacy policies, public statements, and congressional testimony. And when taken very literally, the promise is true: Despite gathering masses of personal data on their users and converting that data into billions of dollars in profits, these tech giants do not directly sell their users’ information the same way data brokers directly sell data in bulk to advertisers.
But the disclaimers are also a distraction from all the other ways tech giants use personal data for profit and, in the process, put users’ privacy at risk, experts say.
Lawmakers, watchdog organizations, and privacy advocates have all pointed out ways that advertisers can still pay for access to data from companies like Facebook, Google, and Twitter without directly purchasing it. (Facebook spokesperson Emil Vazquez declined to comment and Twitter spokesperson Laura Pacas referred us to Twitter’s privacy policy. Google did not respond to requests for comment.)
And focusing on the term “sell” is essentially a sleight of hand by tech giants, said Ari Ezra Waldman, a professor of law and computer science at Northeastern University.
“[Their] saying that they don’t sell data to third parties is like a yogurt company saying they’re gluten-free. Yogurt is naturally gluten-free,” Waldman said. “It’s a misdirection from all the other ways that may be more subtle but still are deep and profound invasions of privacy.”
Those other ways include everything from data collected from real-time bidding streams (more on that later), to targeted ads directing traffic to websites that collect data, to companies using the data internally.
How Is My Data at Risk if It’s Not Being Sold?
Even though companies like Facebook and Google aren’t directly selling your data, they are using it for targeted advertising, which creates plenty of opportunities for advertisers to pay and get your personal information in return.
The simplest way is through an ad that links to a website with its own trackers embedded, which can gather information on visitors including their IP address and their device IDs.
Advertising companies are quick to point out that they sell ads, not data, but don’t disclose that clicking on these ads often results in a website collecting personal data. In other words, you can easily give away your information to companies that have paid to get an ad in front of you.
If the ad is targeted toward a certain demographic, then advertisers would also be able to infer personal information about visitors who came from that ad, Bennett Cyphers, a staff technologist at the Electronic Frontier Foundation, said.
For example, if there’s an ad targeted at expectant mothers on Facebook, the advertiser can infer that everyone who came from that link is someone Facebook believes is expecting a child. Once a person clicks on that link, the website could collect device IDs and an IP address, which can be used to identify a person. Personal information like “expecting parent” could become associated with that IP address.
“You can say, ‘Hey, Google, I want a list of people ages 18–35 who watched the Super Bowl last year.’ They won’t give you that list, but they will let you serve ads to all those people,” Cyphers said. “Some of those people will click on those ads, and you can pretty easily figure out who those people are. You can buy data, in a sense, that way.”
Then there’s the complicated but much more common way that advertisers can pay for data without it being considered a sale, through a process known as “real-time bidding.”
Often, when an ad appears on your screen, it wasn’t already there waiting for you to show up. Digital auctions are happening in milliseconds before the ads load, where websites are selling screen real estate to the highest bidder in an automated process.
Visiting a page kicks off a bidding process where hundreds of advertisers are simultaneously sent data like an IP address, a device ID, the visitor’s interests, demographics, and location. The advertisers use this data to determine how much they’d like to pay to show an ad to that visitor, but even if they don’t make the winning bid, they have already captured what may be a lot of personal information.
With Google ads, for instance, the Google Ad Exchange sends data associated with your Google account during this ad auction process, which can include information like your age, location, and interests.
The advertisers aren’t paying for that data, per se; they’re paying for the right to show an advertisement on a page you visited. But they still get the data as part of the bidding process, and some advertisers compile that information and sell it, privacy advocates said.
In May, a group of Google users filed a federal class action lawsuit against Google in the U.S. District Court for the Northern District of California alleging the company is violating its claims to not sell personal information by operating its real-time bidding service.
The lawsuit argues that even though Google wasn’t directly handing over your personal data in exchange for money, its advertising services allowed hundreds of third parties to essentially pay and get access to information on millions of people. The case is ongoing.
“We never sell people’s personal information and we have strict policies specifically prohibiting personalized ads based on sensitive categories,” Google spokesperson José Castañeda told the San Francisco Chronicle in May.
Real-time bidding has also drawn scrutiny from lawmakers and watchdog organizations for its privacy implications.
In January, Simon McDougall, deputy commissioner of the United Kingdom’s Information Commissioner’s Office, announced in a statement that the agency was continuing its investigation of real-time bidding (RTB), which if not properly disclosed, may violate the European Union’s General Data Protection Regulation.
“The complex system of RTB can use people’s sensitive personal data to serve adverts and requires people’s explicit consent, which is not happening right now,” McDougall said. “Sharing people’s data with potentially hundreds of companies, without properly assessing and addressing the risk of these counterparties, also raises questions around the security and retention of this data.”
And in April, a bipartisan group of U.S. senators sent a letter to ad tech companies involved in real-time bidding, including Google. Their main concern: foreign companies and governments potentially capturing massive amounts of personal data about Americans.
“Few Americans realize that some auction participants are siphoning off and storing ‘bidstream’ data to compile exhaustive dossiers about them,” the letter said. “In turn, these dossiers are being openly sold to anyone with a credit card, including to hedge funds, political campaigns, and even to governments.”
On May 4, Google responded to the letter, telling lawmakers that it doesn’t share personally identifiable information in bid requests and doesn’t share demographic information during the process.
“We never sell people’s personal information and all ad buyers using our systems are subject to stringent policies and standards, including restrictions on the use and retention of information they receive,” Mark Isakowitz, Google’s vice president of government affairs and public policy, said in the letter.
What Does It Mean to “Sell” Data?
Advocates have been trying to expand the definition of “sell” beyond a straightforward transaction.
The California Consumer Privacy Act, which went into effect in January 2020, attempted to cast a wide net when defining “sale,” beyond just exchanging data for money. The law considers it a sale if personal information is sold, rented, released, shared, transferred, or communicated (either orally or in writing) from one business to another for “monetary or other valuable consideration.”
And companies that sell such data are required to disclose that they’re doing so and allow consumers to opt out.
“We wrote the law trying to reflect how the data economy actually works, where most of the time, unless you’re a data broker, you’re not actually selling a person’s personal information,” said Mary Stone Ross, chief privacy officer at OSOM Products and a co-author of the law. “But you essentially are. If you are a social media company and you’re providing advertising and people pay you a lot of money, you are selling access to them.”
But that doesn’t mean it’s always obvious what sorts of personal data a company collects and sells.
In T-Mobile’s privacy policy, for instance, the company says it sells compiled data in bulk, which it calls “audience segments.” The policy states that audience segment data for sale doesn’t contain identifiers like your name and address but does include your mobile advertising ID.
Nevertheless, T-Mobile’s privacy policy says the company does “not sell information that directly identifies customers.”
T-Mobile spokesperson Taylor Prewitt didn’t provide an answer to why the company doesn’t consider advertising IDs to be personal information but said customers have the right to opt out of that data being sold.
So What Should I Be Looking for in a Privacy Policy?
The next time you look at a privacy policy, which few people ever really do, don’t just focus on whether or not the company says it sells your data. That’s not necessarily the best way to assess how your information is traveling and being used.
And even if a privacy policy says that it doesn’t share private information beyond company walls, the data collected can still be used for purposes you might feel uncomfortable with, like training internal algorithms and machine learning models. (See Facebook’s use of one billion pictures from Instagram, which it owns, to improve its image recognition capability.)
Consumers should look for deletion and retention policies instead, said Lindsey Barrett, a privacy expert and until recently a fellow at Georgetown Law. These are policies that spell out how long companies keep data, and how to get it removed.
She noted that these statements hold a lot more weight than companies promising not to sell your data.
“People don’t have any meaningful transparency into what companies are doing with their data, and too often, there are too few limits on what they can do with it,” Barrett said. “The whole ‘We don’t sell your data’ doesn’t say anything about what the company is doing behind closed doors.”
As reported from Reuters, in the 80 page new complaint, the U.S. Federal Trade Commission (FTC) accuses Facebook of illegally monopolizing power. The refiled case includes additional evidence which is intended to support FTC’s case that Facebook dominates the U.S. personal social networking market.
In the headline of its press release, FTC alleges the company resorted to “illegal buy-or-bury- scheme to crush competition after string of failed attempts to innovate”.
“Despite causing significant customer dissatisfaction, Facebook has enjoyed enormous profits for an extended period of time suggesting both that it has monopoly power and that its personal social networking rivals are not able to overcome entry barriers and challenge its dominance,”
AMENDED complaint – federal trade COMMISSION
The FTC voted 3-2 to file the amended lawsuit. They also denied Facebook’s request that Lina Khan be recused, Khan participated in the filing of the new complaint.
The social media giant’s powerful targeting tools appear to be part of Ben Shapiro’s success in growing his audience on the platform
Ben Shapiro, co-founder of The Daily Wire, a conservative media company, has mastered Facebook’s complex algorithms like no one else, posting links to stories from his publication that rank among the top 10 best performing posts on Facebook day after day after day.
What’s the key to his success?
As a recent NPR analysis shows, The Daily Wire’s sensationalist headlines garner a ton of engagement on a platform that rewards explosive content. But The Daily Wire is also a sophisticated user of Facebook’s advertising targeting tools to pinpoint users likely to be receptive to its outrage-driven brand of conservative content, The Markup has found.
Using data from our Citizen Browser project, we pulled targeting information from 241 Daily Wire ads that ran on Facebook between April 15 and July 15, 2021. We found that The Daily Wire largely chose to target people whom Facebook had pegged as interested in Fox News, Donald Trump, Rush Limbaugh, and other conservative mainstays, as well as individuals Facebook determined were characteristically or demographically similar to The Daily Wire’s existing audience members. (See our data here.)
Citizen Browser consists of a panel of roughly 1,800 Facebook users across the country who voluntarily share their Facebook news feed data with The Markup—providing a rare, albeit relatively small, window into what different people see on the platform.
By contrast, The New York Times—one of the largest legacy media publications in the U.S.—took a different tack in its Facebook advertising, targeting users according to the topics of the articles. So, for instance, an article about a band could be targeted to Facebook users with “music” listed in their ad interests. (Facebook says it determines users’ interests based on their past activities on the platform but has been somewhat cagey about how exactly this is done.)
Of the two publications, The Daily Wire used interest targeting more frequently than The New York Times did: 39.3 percent of Daily Wire ads versus 23.5 percent of ads from the Times were targeted in this way.
The table below shows the top 10 interests targeted in sponsored posts from both outlets:
While the Times mostly targets topical interests, of the top 20 interests targeted by The Daily Wire, only one (“American Football”) was not directly tied to conservative media or politics.
The Daily Wire also frequently made use of Facebook’s “lookalike audiences” feature to show content to new audiences of users who do not follow the page but share characteristics with those who do. In our dataset, 37.9 percent of Daily Wire posts used this type of targeting. The New York Times also used this targeting type, albeit rarely: Only 3.6 percent of its sponsored posts in our dataset targeted lookalike audiences.
“As you’re looking at this dataset, to me it shows that mainstream media outlets like The New York Times are still approaching the internet as a collective space in which you could potentially learn about anything, from ‘research’ or ‘science’ to ‘family and relationships,’ ” Francesca Tripodi, an assistant professor at UNC School of Information and Library Science at Chapel Hill, said. “But Daily Wire, if you’re saying, ‘We only want to target people who are interested in conservatism in America,’ that creates this bifurcated or dual internet, and that allows for information to circulate unchecked.”
Facebook advertising is designed to use personal data points about its users to guess what sorts of products they might like, she said, but there’s a fundamental difference between a food brand serving ads to people who like potato chips and a news brand serving information to people who like conservatism.
“[Daily Wire] is using the same tactics that these corporate entities are using but to create siloed interests around information,” Tripodi said.
Neither The Daily Wire nor Facebook responded to multiple requests for comment.
Beyond Facebook’s powerful data-gathering system, The Daily Wire amasses its own information on readers and potential readers.
The Markup also scanned Daily Wire ads in the Facebook ad library, which contains a broader range of ads than those seen by Citizen Browser panelists but does not disclose targeting information. Over a three-month period, from May through July, the ad library displayed 47 unique ads from The Daily Wire. Of these, 22 were survey-style ads prompting users to respond to emotive political questions.
Clicking the ad takes users away from Facebook and onto the dailywire.com domain, where they are asked to enter an email address in order to respond.
Over the same time period, no New York Times ads available in the ad library used this technique.
The Daily Wire’s website also contains an unusually high number of data-gathering trackers.
A scan from Blacklight, a website privacy inspector built by The Markup, on Aug. 4, 2021, turned up 41 ad trackers and 117 third-party cookies on the homepage. By contrast, The Markup’s scan of 100,000 of the most popular websites in September 2020 found an average of seven ad trackers and only three third-party cookies per site.
The site also uses Facebook’s bespoke Pixel tracking code to send data back to the social platform about users who have visited the site, which The Daily Wire can use to further tweak ad targeting and build new lookalike audiences.
“What you’ve shown here is clear evidence of the way in which the radicalization of our society is built on many facets of the algorithm, including the tools provided for ad targeting,” said Cameron Hickey, project director for algorithmic transparency at the National Conference on Citizenship.
Questions about the ethics of using data-driven profiling to target political messages are not new. Perhaps most famously, the British political consulting firm Cambridge Analytica purported to create detailed psychological profiles of Facebook users and shared those with the campaign of former president Donald Trump. While profiling has been a part of politics for decades to some extent, figures ranging from former Facebook insiders to Federal Election Commission officials have raised alarms over the kind of microtargeting that social media allows. (The European Commission is also considering including a ban on microtargeting in its landmark Digital Services Act package, which is making its way through the European Parliament and the Council of the European Union.)
That said, The Daily Wire’s targeting choices are widely accepted as routine, its success on Facebook more of a feature of the platform’s workings than a bug in the system, said Katie Joseff, a research fellow at the Center for Media Engagement at the University of Texas at Austin.
“These platforms, when you look at Facebook and YouTube in particular, they want people on there who are engaging their users because then there’s more users and user time overall,” Joseff said. “So [The Daily Wire] is definitely playing into the structure as it was created and doing it well.”
The Markup found industry fingerprints on at least five bills around the country—weak laws, experts say, that are designed to preempt stronger protections
By: Todd Feathers
Concerned about growing momentum behind efforts to regulate the commercial use of personal data, Big Tech has begun seeding watered-down “privacy” legislation in states with the goal of preempting greater protections, experts say.
The swift passage in March of a consumer data privacy law in Virginia, which Protocol reported was originally authored by Amazon with input from Microsoft, is emblematic of an industry-driven, lobbying-fueled approach taking hold across the country. The Markup reviewed existing and proposed legislation, committee testimony, and lobbying records in more than 20 states and identified 14 states with privacy bills built upon the same industry-backed framework as Virginia’s, or with weaker models. The bills are backed by a who’s who of Big Tech–funded interest groups and are being shepherded through statehouses by waves of company lobbyists.
Meanwhile, the small handful of bills that have not adhered to two key industry demands—that companies can’t be sued for violations and consumers would have to opt out of rather than into tracking—have quickly died in committee or been rewritten.
Experts say Big Tech’s push to pass friendly state privacy bills ramped up after California enacted sweeping privacy bills in 2018 and 2020—and that the ultimate goal is to prompt federal legislation that would potentially override California’s privacy protections.
“The effort to push through weaker bills is to demonstrate to businesses and to Congress that there are weaker options,” said Ashkan Soltani, a former chief technologist for the Federal Trade Commission who helped author the California legislation. “Nobody saw Virginia coming. That was very much an industry-led effort by Microsoft and Amazon. At some point, if multiple states go the way of Virginia, you might not even get companies to honor California’s [rules].”
California’s laws, portions of which don’t go into effect until 2023, create what is known as a “global opt out.” Rather than every website requiring users to go through separate opt-out processes, residents can use internet browsers and extensions that automatically notify every website that a user wishes to opt out of the sale of their personal data or use of it for targeted advertising—and companies must comply. The laws also allow consumers to sue companies for violations of the laws’ security requirements and created the California Privacy Protection Agency to enforce the state’s rules.
“Setting up these weak foundations is really damaging and really puts us in a worse direction on privacy in the U.S.,” said Hayley Tsukayama, a legislative activist for the Electronic Frontier Foundation. “Every time that one of these bills passes, Virginia being a great example, people are saying ‘This is the model you should be looking at, not California.’ ”
Amazon did not respond to requests for comment, and Microsoft declined to answer specific questions on the record.
Industry groups, however, were not shy about their support for the Virginia law and copycats around the country.
The Virginia law is a “ business and consumer friendly approach” that other states considering privacy legislation should align with, The Internet Association, an industry group that represents Big Tech, wrote in a statement to The Markup.
Big Tech’s Fingerprints Are All Over State Privacy Fights
In testimony before lawmakers, tech lobbyists have criticized the state-by-state approach of making privacy legislation and said they would prefer a federal law. Tech companies offered similar statements to The Markup.
Google spokesperson José Castañeda declined to answer questions but emailed The Markup a statement: “As we make privacy and security advancements to protect consumers, we’ll continue to advocate for sensible data regulations around the world, including strong, comprehensive federal privacy legislation in the U.S.”
But at the same time, the tech and ad industries have taken a hands-on approach to shape state legislation. Mostly, industry has advocated for two provisions. The first is an opt-out approach to the sale of personal data or using it for targeted advertising, which means that tracking is on by default unless the customer finds a way to opt out of it. Consumer advocates prefer privacy to be the default setting, with users given the freedom to opt in to certain uses of their data. The second industry desire is preventing a private right of action, which would allow consumers to sue for violations of the laws.
The industry claims such privacy protections are too extreme.
“That may be a bonanza for the trial bar, but it will not be good for business,” said Dan Jaffe, group executive vice president for government relations for the Association of National Advertisers, which has lobbied heavily in states and helped write model federal legislation. TechNet, another Big Tech industry group that has been deeply engaged in lobbying state lawmakers, said that “enormous litigation costs for good faith mistakes could be fatal to businesses of all sizes.”
Through lobbying records, recordings of public testimony, and interviews with lawmakers, The Markup found direct links between industry lobbying efforts and the proliferation of these tech-friendly provisions in Connecticut, Florida, Oklahoma, and Washington. And in Texas, industry pressure has shaped an even weaker bill.
Additionally, The Markup found a handful of states—particularly North Dakota and Oklahoma—in which tech lobbyists have stepped in to thwart efforts to enact stricter laws.
Connecticut
The path of Connecticut’s bill is illustrative of how these battles have played out. There, state Senate majority leader Bob Duff introduced a privacy bill in 2020 that contained a private right of action. During the bill’s public hearing last February, Duff said he looked out on a room “literally filled with every single lobbyist I’ve ever known in Hartford, hired by companies to defeat the bill.”
The legislation failed. Duff introduced a new version of it in 2021, and it too died in committee following testimony from interest groups funded by Big Tech, including the Internet Association and The Software Alliance.
According to Duff and Sen. James Maroney, who co-chairs the Joint Committee on General Law, those groups are now pushing a separate privacy bill, written using the Virginia law as a template. Duff said lawmakers “had a Zoom one day with a lot of big tech companies” to go over the bill’s language.
“Our legislative commissioner took the Virginia language and applied Connecticut terminology,” Maroney said.
That industry-backed bill passed through committee unanimously on March 23.
“It’s an uphill battle because you’re fighting a lot of forces on many fronts,” Duff said. “They’re well funded, they’re well heeled, and they just hire a lot of lobbyists to defeat legislation for the simple reason that there’s a lot of money in online data.”
Google has spent $100,000 lobbying in Connecticut since 2019, when Duff first introduced a consumer data privacy bill. Apple and Microsoft have each spent $124,000, Amazon has spent $116,000, and Facebook has spent $155,000, according to the state’s lobbyist reporting database.
Microsoft declined to answer questions and instead emailed The Markup links to the testimony its company officials gave in Virginia and Washington.
The Virginia model “is a thoughtful approach to modernize United States privacy law, something which has become a very urgent need,” Ryan Harkins, the company’s senior director of public policy, said during one hearing.
Google declined to respond to The Markup’s questions about their lobbying. Apple and Amazon did not respond to requests for comment.
Oklahoma
In Oklahoma, Rep. Collin Walke, a Democrat, and Rep. Josh West, the Republican majority leader, co-sponsored a bill that would have banned businesses from selling consumers’ personal data unless the consumers specifically opted in and gave consumers the right to sue for violations. Walke told The Markup that the bipartisan team found themselves up against an army of lobbyists from companies including Facebook, Amazon, and leading the effort, AT&T.
AT&T lobbyists persuaded House leadership to delay the bill’s scheduled March 2 hearing, Walke said. “For the whole next 24-hour period, lobbyists were pulling members off the house floor and whipping them.”
Walke said to try to get the bill through the Senate, he agreed to meetings with Amazon, internet service providers, and local tech companies, eventually adopting a “Virginia-esque” bill. But certain companies remained resistant—Walke declined to specify which ones—and the bill died without receiving a hearing.
AT&T did not respond to questions about its actions in Oklahoma or other states where it has fought privacy legislation. Walke said he plans to reintroduce the modified version of the bill again next session.
Texas
In Texas, Rep. Giovanni Capriglione first introduced a privacy bill in 2019. He told The Markup he was swiftly confronted by lobbyists from Amazon, Facebook, Google, and industry groups representing tech companies. The state then created a committee to study data privacy, which was populated in large part by industry representatives.
Facebook declined to answer questions on the record for this story.
Capriglione introduced another privacy bill in 2021, but given “Texas’s conservative nature,” he said, and the previous pushback, it doesn’t include any opt-in or opt-out requirement or a private right of action. But he has still received pushback from industry over issues like how clear and understandable website privacy policies have to be.
“The ones that were most interested were primarily the big tech companies,” he said. “I received significant opposition to making any changes” to the status quo.
Washington
The privacy bill furthest along of all pending bills is in Washington, the home state of Microsoft and Amazon. The Washington Privacy Act was first introduced in 2019 and was the inspiration for Virginia’s law. Microsoft, Amazon, and more recently Google, have all testified in favor of the bill. It passed the state Senate 48–1 in March.
A House committee considering the bill has proposed an amendment that would create a private right of action, but it is unclear whether that will survive the rest of the legislative process.
Other States
Other states—Illinois, Kentucky, Alabama, Alaska, and Colorado—have Virgina-like bills under consideration. State representative Michelle Mussman, the sponsor of a privacy bill in Illinois, and state representative Lisa Willner, the sponsor of a bill in Kentucky, told The Markup that they had not consulted with industry or made privacy legislation their priority during 2021, but when working with legislative staff to author the bills they eventually put forward, they looked to other states for inspiration. The framework they settled on was significantly similar to Virginia’s on key points, according to The Markup’s analysis.
The sponsors of bills in Alabama, Alaska, and Colorado did not respond to interview requests, and public hearing testimony or lobbying records in those states were not yet available.
The Campaign Against Tougher Bills
In North Dakota, lawmakers in January introduced a consumer data privacy bill that a coalition of advertising organizations called “the most restrictive privacy law in the United States.” It would have included an opt-in framework, a private right of action, and broad definitions of the kind of data and practices subject to the law.
It failed 75–19 in the House shortly after a public hearing in which only AT&T, data broker RELX, and industry groups like The Internet Association, TechNet, and the State Privacy and Security Coalition showed up to testify—all in opposition. And while the big tech companies didn’t directly testify on the bill, lobbying records suggest they exerted influence in other ways.
The 2020–2021 lobbyist filing period in North Dakota, which coincided with the legislature’s study and hearing on the bill, marked the first time Amazon has registered a lobbyist in the state since 2018 and the first time Apple and Google have registered lobbyists since the state began publishing lobbying disclosures in 2016, according to state lobbying records.
A Mississippi bill containing a private right of action met a similar fate. The bill’s sponsor, Sen. Angela Turner-Ford, did not respond to an interview request.
While in Florida, a bill that was originally modeled after California’s laws has been the subject of intense industry lobbying both in public and behind the scenes. On April 6, a Florida Senate committee voted to remove the private right of action, leaving a bill substantially similar to Virginia’s. State senator Jennifer Bradley, the sponsor of Florida’s bill, did not respond to The Markup’s request for comment.
Several bills that include opt-in frameworks, private rights of action, and other provisions that experts say make for strong consumer protection legislation are beginning to make their way through statehouses in Massachusetts, New York, and New Jersey. It remains to be seen whether those bills’ current protections can survive the influence of an industry keen to set the precedent for expected debate over a federal privacy law.
If the model that passed in Virginia and is moving forward in other states continues to win out, it will “really hamstring federal lawmakers’ ability to do anything stronger, which is really concerning considering how weak [that model] is,” said Jennifer Lee, the technology and liberty project manager for the ACLU of Washington. “I think it really will entrench the status quo in allowing companies to operate under the guise of privacy protections that aren’t actually that protective.”
Platform wars are heating up and influencers may be prime beneficiaries…
Something strange is happening in social media: influencers are getting paid, sometimes directly by platforms.
To clarify; there have always been ways for creators with a large following to monetize their stats. Mainly, however, until recently that mostly involved sponsorships and affiliate merchandise, and the like.
On top of the efforts required to create winning content, getting paid for it was an additional job and creators got little assistance from the greatest beneficiaries of the work: the host platforms themselves.
Suddenly, it seems, the value of creators in bringing and keeping traffic for the platforms is so high, as a war rages between platforms for that traffic, that some have gone as far as initiating new programs to pay influential content makers directly.
Naturally, YouTube has had a monetization program that requires elevated status to qualify for and then takes a more than 30% cut of the proceeds, but on the whole payment for creative content production has been minimal for all but the most massive stars in the social media firmament. Now, that appears to be changing, and fast.
Snap, a once hot destination, is trying to boost its attractiveness by paying out $1 million per day for popular posts. TikTok, the fastest growing platform recently, has also set up a fund to pay out to creators and says it will increase the fund to $1 billion.
All of this is not going unnoticed by the platforms with the most traffic, Facebook and its owned entity Instagram, and, in an unprecedented move, payments are beginning to flow on those platforms also. Twitter, Clubhouse and others have various plans in the works as well.
There’s a massive shift toward coveting creators as a result of competition for traffic and members
What this all boils down to is two things. There’s a war going on (in reality battles left and right in many areas of internet dominance) and the spoils are traffic growth, and that growth is only possible for the platforms if creators migrate in and stick around.
As long as Facebook, Instagram and Google’s YouTube were untouchable monopolies they did not need to admit that they needed the allegiance of creators and influencers.
As the only game in town, each in a different monopolized neighborhood, there was literally no where for the creators to run to. No more. Mainly TikTok and now upstarts like Clubhouse are changing the landscape and that is scary to the legacy platforms.
Anecdotal evidence points to the ability for talent to garner views and followers, via the algorithm settings that either promote or hide content from prospective consumers, as the prime mover, at least initially, for the creators to favor TikTok.
Stories abound of creators that, within days or weeks, were able to get millions of views due to the “democratic” openness of the TikTok system for featuring content based on less restrictive algorithms than the entrenched platforms.
The once invincible behemoths at Facebook and Google let greed get the best of them. It has been literally years since organic reach, the ability to get views and traffic just on the quality of the content, was possible on facebook and the price to reach an audience, with paid posts, just kept going higher and higher.
Now, due to this tectonic shift in power, from the platforms to the influencers and users, there is, unbelievably, a situation emerging where Facebook must appease the talent and creativity of the content creators if they want to remain relevant.
Pending antitrust actions and privacy issues are just adding to the shifting status and uncertain future of social media
In a sense, there was always a kind of unwritten rule of social media: the owners and creators of the platforms retained all the money and power with none of the liability or labor requirements.
That relationship, which is like slaves who built the great pyramids, but without the allowance for food or shelter, was doomed from the start as it is based on a lie.
Ultimately the platform has very little to offer, technological and software designs are easily replicated theses days, and these platforms are not in the business of generating any of content, yet they expect that content to be created for free by users.
This ridiculous valueless and vampiric scam has been lionized and worshiped as the ultimate internet success formula for more than a decade.
Facebook, and Mark Zuckerberg, have stood as the ultimate arbiters of how to become obscenely rich by enticing the world to work and create content for your platform for zero renumeration.
Once a company, coincidentally one that originated in China, came along and decided not to worship the Zuckerberg formula, but to undercut it by giving creators an ever-so-slightly less terrible deal, the spell was broken.
Next, it was only a matter of time before the war over the real value began: the content itself that users and particularly top creators on each platform provide.
Not to say that TikTok is heroic or intentionally upset the apple cart as a result of any foresight or altruism, this is just the inevitable outcome of a failed and corrupt system eventually becoming mature and collapsing (slowly) under its own stupidity.
For now, this slight reprieve from endless exploitation is an extremely hopeful sign. Let’s hope that creator payouts and the competition for content, real content that has value regardless of which platform hosts it, will continue to rise in stature.
Any creators or influencers out there who are listening, do what you do best which is create, and now add the option to sell your services to the highest bidder to your toolkit and keep your eyes and ears open for the next, even more accommodative platform to emerge from the muck. Then go there.
Long-time adviser and spokesperson for the Trump campaign, Jason Miller, stated on on Fox’s “MediaBuzz” that the former guy would be “returning to social media in probably about two or three months.”
In typical fashion spokesperson says it will be huge
Next he bragged that his return to social media would be via “his own platform” and that this new network would garner “tens of millions” of users and in his opinion would also “completely redefine the game.”
“It’s going to completely redefine the game, and everybody is going to be waiting and watching to see what President Trump does, but it will be his own platform.”
—Jason Miller, Trump Spokesperson
This news comes at a time when the furor of constant rage tweeting from the former guy has finally died down. It remains to be seen if this announcement is credible as there are pending legal and financial challenges that could potentially stand in the way of such an undertaking.
Trump has yet to resurface on any social media platform, are we in the clear?
The proverbial nail in the Twitter coffin for Trump has finally been pounded home. Based on a statement from a Twitter spokesperson, once you are removed from the platform, you are removed, with no exceptions. So that means, regardless of his potential future run for president in 2024, it has been confirmed, Trump will never be allowed to share a rant via a tweet.
Of course, if the current impeachment trial in the Senate is successful in one of its aims, he will also be banned forever from seeking public office.
During an interview with CNBC, Twitter CFO, Ned Segal, spoke in detail, confirming that Trump will not be allowed back on the platform, ever.
"The way our policies work, when you're removed from the platform, you're removed from the platform whether you're a commentator, you're a CFO or you are a former or current public official," says $TWTR CFO @nedsegal on if President Trump's account could be restored. pic.twitter.com/ZZxascb9Rz
“When you’re removed from the platform, you’re removed from the platform, whether you’re a commentator, you’re a CFO, or you are a former or current public official,” said Segal. “Remember, our policies are designed to make sure that people are not inciting violence. And if anybody does that, we have to remove them from the service, and our policy is not to allow people to come back.”